
Although I'm quite impressed by Rust language recently, Kotlin is still my favorite language. In this post, I will share the major reasons which convinced me to leave Java two years ago. It won't cover every bright side of Kotlin language, but will be enough to make my point.
TL:DR
Java the Good Parts and the Bad Parts
If you ever asked me if Java is a good programming language, I would definitely say yes. Compare to languages such as C++, VB, Javascript. Writing code in Java is much more pleasant. More specifically, its virtue including but not limited to:
- Cross Platform
- Statically Typed
- Automatic Memory Management
- Open Community
- (After all, When I could not make a living by writing some fancy languages. It was Java gave me a job so that I could complain it all day.)
Anyway, just like other elder languages, Java has made many design mistakes, I won't dive into the language design topic here, as I'm not a specialist in programming language (or any other) field. I just want to share some issues that do bother me, from a mediocre programmer's perspective, then see how they are solved in Kotlin.
Null safety
The first problem is the notorious Null reference(aka The billion-dollar mistake), to people who don't understand why it is a design mistake, considering the following example, suppose some libraries author wrote a method that returns a User's full name.1
2
3public interface User {
String getFullName();
}
then you want to write a function which tests if a user is John Snow, you may end up with writing code like this:1
2
3public boolean isJohnSnow(User user) {
return user.getFullName().equals("John Snow");
}
As a Java novice, You test your code and it works smoothly, then you push it to production. Now, Your workmates are able to make use of it. They may want to say something to John.1
2
3
4
5public void greeting(User user) {
if (isJohnSnow(user)) {
sendMessage(user, "You know nothing!");
}
}
Someday, Your workmates complain that your method throws an NPE, because no one says the getFullName() method is not allowed to return a null, which indicates that they don't know the user's full name. So you take the blame and say sorry to your workmates, then you fix your code immediately:1
2
3
4
5public Boolean isJohnSnow(User user) {
String fullName = user.getFullName();
if (fullName == null) return null;
return fullName.equals("John Snow");
}
You change the method signature to return the boxed type and return a null reference indicates you don't know if the user is John Snow. Thanks to auto unboxing, none of your workmates will notice this change, until the day their code starts to throw NPE...
So how do we avoid this problem in Java? We do have some options:
- Check before calling
A naive way would be whenever you call a method, you check its implementation and find out if the method will return null. It is naive because the author of the method can change its implementation at any time. Also, in the preceding case, you may have to check every class which implements a User interface, this is not really practical. Moreover, the whole point of OOP and statically typed is you don't need to care about implementations, in most cases the signature of a method will tell you enough information. - Check after returning
Another possible option is being extremely pessimistic, which means you cannot trust every object returned by other methods, although most of them never return a null reference, you still have to writeif(returned == null)everywhere, because you never read their documents and their signature never says return null is not allowed. However, as you can guess, this is not practical either, because writing and reading such tedious code drives people crazy. - Return a meaningful default value in place of null.
As NPE is such an annoying thing, you may think we can avoid it by not using Null reference. For example, we can return an empty String to indicate we don't know a user's full name. Again it's not a good idea, empty string and "missing value" are not the same. In fact, if you want to express a "missing" value, there is no other thing better than a null reference, every programmer can understand its meaning. After all, I never said It is Null's fault to cause a NullPointerException. - Optional
If your method sometimes returns a "missing value", use Optional as the return type is a very good option. However, it doesn't solve all the problems because an Optional itself is a reference type, which means it could be a null reference. - Nullable annotation
Another good option to reduce the risk of NPE is to use an annotation that indicates your method may return a null value. For example:Then the IDEs such as Idea can warn you when you forget to handle the possible null value. However, you are not guaranteed to get the benefit from doing this when you switch to another IDE.1
2
3
4public interface User {
String getFullName();
}
As you can see, there is no perfect solution to avoid the annoying NPE. Before introducing how modern languages(Kotlin, Swift, Typescript in StrictNull model) solve this problem, let's think about why Tony Hoare said this is a mistake. In my point of view, it's a quintessential example of violating the Liskov substitution principle (However, LSP is almost twenty years later than Hoare invented Null reference). Namely, null is a subtype of any other reference type in Java, but it doesn't have their behavior.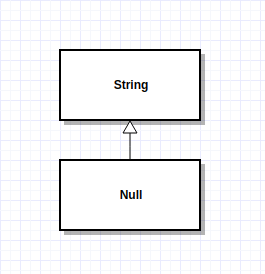
More specifically, in our preceding example, you can see that the Java compiler allow the null reference to go anywhere a String can go, but it doesn't have the String's behavior, it doesn't support equals, startWith operation. That's why we get NPE.
On the contrary, In modern languages like Kotlin. The relation between Nullable String, String, null is depicted as follows.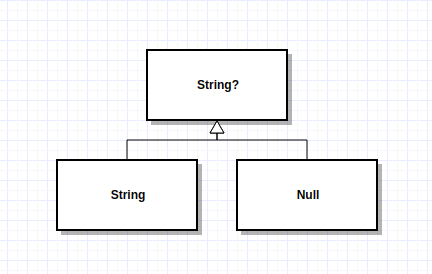
String and null are both the subtype of nullable String Type(in Kotlin it is denoted as String?), but null is not a String anymore, which means String and null can go anywhere a String? can go. but if your method signature says you are returning a String value, the compiler will stop you from returning a null. Thus the caller of your method can safely call String's methods on the returned value without checking the value first. And if you claim that your method will return a Nullable String? The compiler will force the caller to check the returned value before any further processing. Moreover, Kotlin also provides several operators to help you handle Nullable type easily and safely, such like ?., ?:, as?, Check out the official documentation to get more information about them.
Immutable Collection
Another example of violating the Liskov's principle is Java collection API. Here is my story, when I was a beginner, I found that Arrays.asList comes very handy, so I used to write something like:1
List<String> list = Arrays.asList("foo", "bar");
To ensure everything is ok, I even checked its source code.1
2
3
4
5
6// source code of Arrays.asList
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
As I expected, it returns my favorite ArrayList. Later somewhere, I add an element into the list as usual.1
list.add("baz");
So what could possibly go wrong? I can still remember how shocked I was when I found out it throws a UnsupportedOperationException at runtime, turns out the ArrayList is just a private class defined in Arrays.java, it doesn't support add operation.
In Java, for some historical reason (I guess), UnmodifiableCollection is a subtype of Collection. So are UnmodifiableSet, UnmodifiableList etc. which means if you get a List returned by other people, you simply don't know if you can add an element into it. Just like the previous NPE problem, you can either read the documentation if there is one, or go through the source code to find out its actual return type. Again, these options are not practical for exactly the same reason, you cannot read the documentation or source code before every method call.
Luckily, mutate a List which is not created by yourself is not a good practice, so I tend to ignore the mutate operation in List interface, and treat every List instance as Immutable.
In Kotlin, Collection and MutableCollection are separated interface, more precisely, MutableCollection is a subtype of Collection. If you have a Collection interface, the compiler won't let you mutate it, If you have a MutableCollection instance, you are promised that you can mutate it, if your method expects a Collection, you might get a MutableCollection, but not vice versa, everything is simple and clear.
Collection Operation
Java8 introduced the Stream API, It allows people manipulate collections in a declarative way, which means you only need to specify what you need, not how you do, leave the implementation detail to the framework. Also, thanks to its lazy fact, a lot of optimization can be done under the hood. Furthermore, you can even change your stream to "parallel" mode any time you want, how awesome it is! But let me ask you a question, what was the last time you change your stream to parallel?
For me, I never do this. Most time I'm dealing with a collection contains no more than 1000 elements, I don't really care if it could be optimized a little bit, it doesn't make observable difference anyway. Besides, If somehow my collection grows to millions of elements. I don't think the underlying optimization can save me from rewrite my code, neither switching to parallel mode will do.
While I can't see what it is good for, I do see its drawback. It complicates things a lot. That is, if you are a programmer who has already been familiar with languages such as Javascript, Python. Highly likely you are still unable to figure out how map, filter, reduce are done in Java without reading the f* manual. Due to the Stream, Collector class make heavily use of overload, generic methods, you usually cannot get useful hints when you stuck at some point, the compiler may produce inscrutable, even completed irrelevant error message.
Even though you did everything right, the API still has its own limit. For example, If I need to get the index of current iterating element, I have no choice but rewrite the whole method calling chain back to the old "for loop" form. You may argue the following code could do it the stream way.1
2
3
4
5
6IntStream.range(0, list.size())
.boxed()
.collect(Collectors.toMap(
e -> e, // index
list::get // element
));
However, It's not acceptable to me. Not to mention the code hides the intention, its performance may also be a problem, as you can see, it takes N^2 time to traverse over a LinkedList.
Altogether, It gives me the sense that the authors of the API just have to be so smart, inventing something simple is insulting their intelligence.
In contrast, most collection operation in Kotlin is implemented by inline function, here is the source code of mapIndex method.1
2
3
4
5
6
7
8
9
10public inline fun <T, R> Iterable<T>.mapIndexed(transform: (index: Int, T) -> R): List<R> {
return mapIndexedTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapIndexedTo(destination: C, transform: (index: Int, T) -> R): C {
var index = 0
for (item in this)
destination.add(transform(index++, item))
return destination
}
The inline modifier indicates the implementation will be inline to the call site so that it won't introduce extra runtime overhead. In other words, it works just like a kind of syntactic sugar. Later, if you find you do need the stream behavior, thanks to the compatibility between Kotlin and Java, the stream API is still there for you.
With Kotlin type induction and the powerful Idea, you can peek your result type on each step, therefore it is easy to figure out what is going wrong, here is a simple example shows how collection operation in Kotlin looks like.
Template Code
Java is doing an excellent job if you get paid by counting your code lines. If you want to get rich, all you need to do is create some so called "POJO", add some fields. Here is an example, basically just 13 lines of code.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Foo {
private String field1;
private String field2;
private String field3;
public static class Bar {
private String field1;
private String field2;
private String field3;
}
public static class Baz {
private String field1;
private String field2;
private String field3;
}
}
Then, let IDE help finish your job. When it gets done, it automatically becomes hundreds of lines.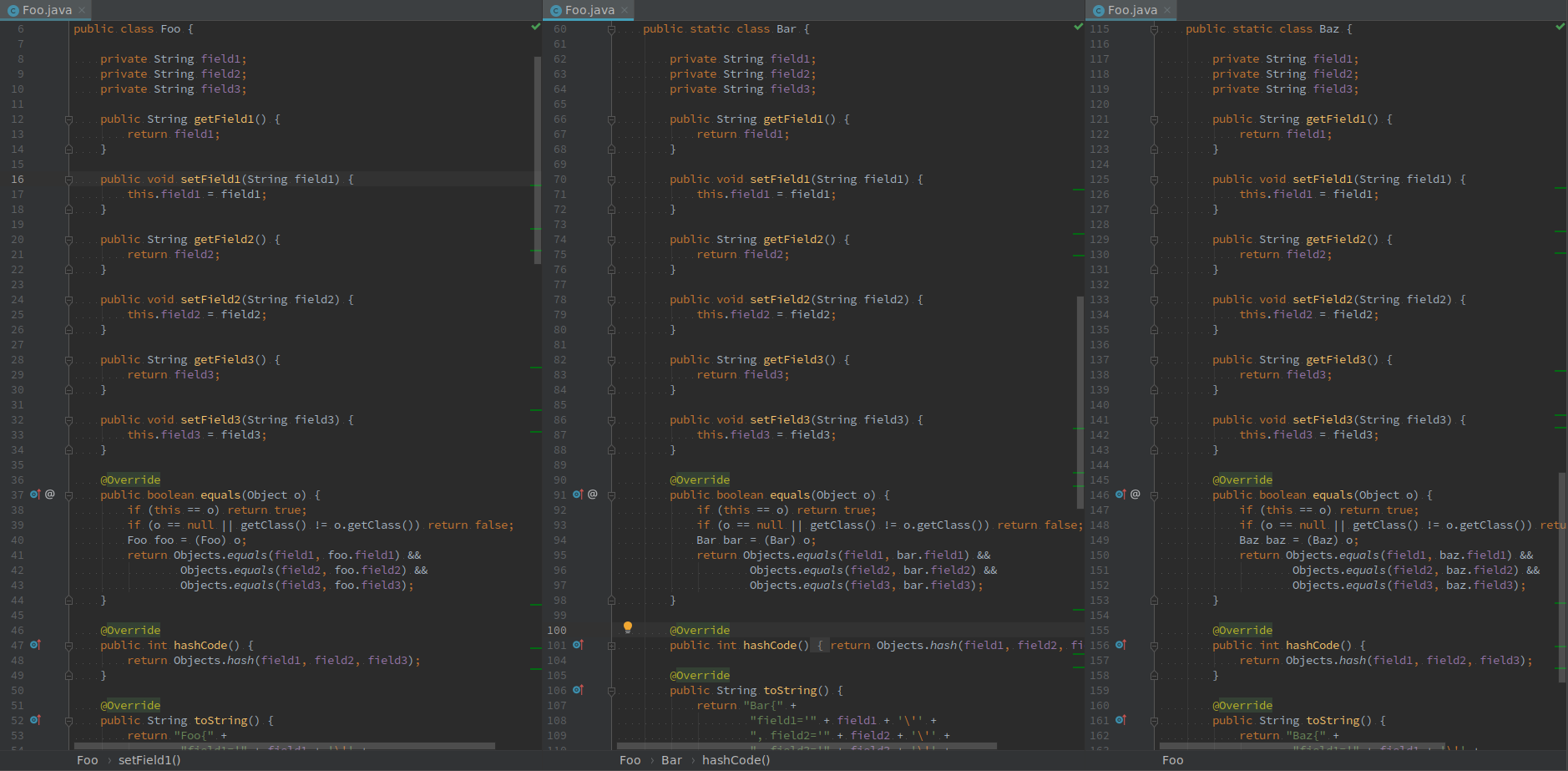
How amazing it is!
Sadly, in Kotlin, it will still be 13 lines.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19data class Foo(
var field1: String,
var field2: String,
var field3: String
) {
data class Bar(
var field1: String,
var field2: String,
var field3: String
)
data class Baz(
var field1: String,
var field2: String,
var field3: String
)
}
The data keyword covers all the equals, hashcode,toString functionality, and even more powerful.
Effective Java
Effective Java(we refer to edition 2 here) is a great book in Java field, it helps me avoiding tons of pitfall in Java, in this section, you will see how Kotlin adhere its advice.
Singleton (Item 3: Enforce the singleton property with a private constructor or an enum type)
I have been asked how to implement a Singleton once in an interview, because it is not trivial in Java (Considering the setAccessible, Serializable factor). As the book suggests, The best way to implement a singleton is to use a single-element enum type.1
2
3
4
5
6public enum Elvis {
INSTANCE;
// properties
// methods
}
However, I think this approach is somehow hacky, the enum keyword is not designed for this purpose, no one will understand why use enum here at first glance, hence it does make it a fair interview question.
Sadly again, you cannot ask a Kotlin programmer how to implement a Singleton because it is so damn easy and obvious.1
2
3
4
5
6object Elvis {
// properties
// methods
}
Immutability (Item 15: Minimize mutability)
I will not count the benefits of making object immutable here. Even a Javascript(a single-threaded language) programmer will know its importance(see Redux and Immutable.js). Not to mention the situation in Java.
Nonetheless, it really cost a lot to make a Java POJO immutable. You may argue how hard it could be? Just go make everything final. Let's see, suppose we have a "POJO" which have five fields.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public final class Sample {
private final String field1;
private final Boolean field2;
private final Integer field3;
private final Float field4;
private final Double field5;
public Sample(String field1, Boolean field2, Integer field3, Float field4, Double field5) {
this.field1 = field1;
this.field2 = field2;
this.field3 = field3;
this.field4 = field4;
this.field5 = field5;
}
// getter is omitted
}
Admittedly, create such a class is not hard, but work with it could bugs your head out. Create such an instance will like1
Sample sample1 = new Sample("", true, 0, 0f, 0d);
I promise you that no one will understand the meaning of each parameter include yourself. Suppose you want to change the field2 and create a new instance it will be like1
Sample sample2 = new Sample(sample1.getField1(), false, sample1.getField3(), sample1.getField4(), sample1.getField5());
If this is acceptable to you, I sincerely wish you never need to add a new field to that class. I know this kind of problem can be solved by following the builder pattern, but most programmers are lazy, they won't write the code until the day they have to. That is, in the ideal Java world, we should make a class immutable unless we have a good reason not to do so. In practical, we leave a class mutable unless we know it will cause problems in advance.
In Kotlin, create and work with an immutable classes is even easier than the mutable one.1
2
3
4
5
6
7data class Sample(
val field1: String = "",
val field2: Boolean = false,
val field3: Int = 0,
val field4: Float = 0f,
val field5: Double? = null
)
To "minimize mutability", Kotlin class are final by default, with default parameter and naming parameter, you can do something like.1
2
3
4
5
6
7
8
9
10// they are all valid
val sample1 = Sample(
field1 = "foo",
field2 = true,
field3 = 1,
field4 = 1f,
field5 = 1.0
)
val sample2 = Sample(field2=true)
val sample3 = Sample()
To duplicate a new instance, you just need to specify the changing part.1
val sample4 = sample3.copy(field2=true, field3=2)
Delegation (Item 16: Favor composition over inheritance)
It is common that an OOP beginner treats inheritance as a way to reuse code. As the example in the book says, if we need to create an InstrumentedHashSet, one may do something like this:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class InstrumentedHashSet<E> extends HashSet<E> {
// The number of attempted element insertions
private int addCount = 0;
public InstrumentedHashSet() { }
public boolean add(E e) {
addCount++;
return super.add(e);
}
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
This is totally reasonable because we don't want to repeat ourselves. By extending HashSet, we can get the full functionality of the Set interface, and we only need to override the method which we want to customize. However, the code doesn't work, even if it does work, we still should not do this, because the HashSet is not designed for inheritance, you should read the book if you fail to understand this, we won't dive deep here. Anyway, the book suggests we use composition and forwarding instead, That is:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// Wrapper class - uses composition in place of inheritance
public class InstrumentedSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedSet(Set<E> s) {
super(s);
}
public boolean add(E e) {
addCount++;
return super.add(e);
}
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
// Reusable forwarding class
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s;
public ForwardingSet(Set<E> s) { this.s = s; }
public void clear() { s.clear();}
public boolean contains(Object o) { return s.contains(o);}
public boolean isEmpty() { return s.isEmpty();}
public int size() { return s.size();}
public Iterator<E> iterator() { return s.iterator();}
public boolean add(E e) { return s.add(e);}
public boolean remove(Object o) { return s.remove(o);}
public boolean containsAll(Collection<?> c) { return s.containsAll(c);}
public boolean addAll(Collection<? extends E> c) { return s.addAll(c);}
public boolean removeAll(Collection<?> c) { return s.removeAll(c);}
public boolean retainAll(Collection<?> c) { return s.retainAll(c);}
}
As you can see, The ForwordingSet does nothing but forward every method call to an existing Set implementation. As the book says: "It's tedious to write forwarding methods, but you have to write the forwarding class for each interface only once." However, even mediocre programmers like me don't like write such code, it just like the meaningless getter,setter in Java, even worse, the IDE may not be able to generate such code for you.
In Kotlin, it is done by delegation, the equivalent code is1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class InstrumentSet<T>(
private val set: MutableSet<T>
) : MutableSet<T> by set {
var addCount = 0
private set
override fun add(element: T): Boolean {
addCount++
return set.add(element)
}
override fun addAll(elements: Collection<T>): Boolean {
addCount += elements.size
return set.addAll(elements)
}
}
The by keyword indicates we are forwarding every Set method to the set property.
Variance (Item 28: Use bounded wildcards to increase API flexibility)
Suppose we are writing a log method, In some cases, we may want to reduce the runtime cost by taking a Supplier as a parameter.1
2
3
4
5public static void log(Supplier<Object> supplier) {
if (isLogEnabled) {
System.out.println(supplier.get());
}
}
With this API, If get the logging message is expensive, we can call debug(() -> expensiveToStringOperation()) instead of debug(expensiveToStringOperation())(the latter one need to evaluate the "expensiveToStringOperation" even when isLogEnabled is false, this is as known as call by value). Suppose somehow we have already defined the Supplier's type as Supplier<String>, we cannot pass it in since Supplier<String> is not a subtype of Supplier<Object>. Although this as a totally safe operation because if the method is able to handle any Object, It must also be able to handle a String.1
2
3
4
5Supplier<String> supplier = () -> "hello world";
// doesn't compile
Console.log(supplier);
// doesn't compile either
Console.log((Supplier<Object>) supplier);
To increase the flexibility of our log method, as the Effective Java recommended, we should rewrite our log method as1
2
3
4
5
6
7// Supplier<? extends Object> can be simplified to Supplier<?>
// But I leave it here to explain the bound
public static void log(Supplier<? extends Object> supplier) {
if (isLogEnabled) {
System.out.println(supplier.get());
}
}
Such that we can pass the Supplier<String> in. However, write these wildcard types correctly might be tricky, the book also introduces a mnemonic to help us determine which wildcard type to use, which says:
PECS stands for producer-extends, consumer-super
That is, if we only use the parameter as a producer, we should use the <? extends T> form, else if we only use the parameter as a consumer, we use the <? super T> form. In the previous example, we only use the supplier as a producer, so we use extends bound.
However, in this case, the Supplier can
But the point is, how could you ever use Supplier as a Consumer? It is not possible. In other words, a Supplier<String> should always be a subtype of Supplier<Object>, no matter how do you use it. Similarly, a Consumer<Object> should always be a subtype of Consumer<String>, this is so called covariance and contravariance.
In Kotlin, if your class only "produce" or "consume" a type parameter. The compiler will help you decide which kind of "variance" your class is allowed. Therefore, you don't need to write the wildcard everywhere, the Supplier<String> will automatically become subtype of Supplier<Object>, the following code compiles correctly.1
2
3
4val supplier: Supplier<String> = Supplier {
"hello world"
}
Console.debug(supplier)
In Kotlin, The bounded wildcard parameter is only needed when your parameter class can be used as both consumer and producer, and your method only uses it as consumer or producer. Although, it is extremely rare to encounter such a situation, A possibly but not practical signature would be1
2
3fun <T> copyData(src: Deque<out T>, dest: Deque<in T>) {
dest.addAll(src)
}
I guess this time, the mnemonic should be updated to:
POCI stands for producer-out, consumer-in
Conclusion
Java is dear, Kotlin is dearer.