
今天偶然间读到了 Martin Kleppmann 与 Salvatore Sanfilippo 关于 Redlock 算法是否”安全“的讨论,觉得挺有启发的,因此打算把目前的思考记下来。由于这篇文章比较长,这里提前剧透我的结论,“所有带有效期的分布式锁本质上都是不“安全”的,只有“安全”的资源服务,没有“安全”的分布式锁”。
背景
Martin Kleppmann 是剑桥大学分布式系统领域的一名研究员,同时也是 Designing Data-Intensive Applications 这本书的作者,他在个人博客中发了一篇文章 How to do distributed locking,其中涉及了大量对 Redlock 算法安全性的质疑,Salvatore Sanfilippo(Redis 的创始人,也是这里 Redlock 算法的作者)随后发表 Is Redlock safe? 回应这些质疑,这篇文章总结了这两篇文章讨论的重点和我对这些问题的想法。
术语和约定
像之前的翻译文章一样,一些专业术语翻译成中文反而不好理解,这里提前解释一下这些术语。
- safety 属性
简单说 safety 就是保证不会有坏事发生。如果该属性被违背,我们一般可以确切的知道它们在哪个时间点被违背,比如说集合元素的唯一性就是 safety 属性。如果一个集合插入了一个重复元素,那么在插入的这个时间点违反了唯一性这个 safety 属性。(注意不要混淆这里的 safety 属性和文章标题中“安全”一词的含义) - liveness 属性
简单说,liveness 就是保证好事最终会发生。比如说最终一致性就是 liveness 属性(一般 liveness 属性定义中都包含”最终“二字)
"Intuitively, a safety property describes what is allowed to happen, and a liveness property describes what must happen."
为了更好的描述问题,我们先定义下面三种角色:
- 资源服务:即需要被锁保护的资源。
- 锁服务:即本文 Redlock 算法扮演的角色。
- 锁用户:申请与释放锁的客户端。(下文可能简称为用户)
使用分布式锁的目的主要有两种,分别是:
- 效率(Efficiency):通过锁来避免多次做重复的工作,计算重复的内容等等。这种场景下即便偶然出现多个用户同时持有锁,并同时与资源服务发生交互,也是可以忍受的。
- 正确性(Correctness):也就是文章标题所说的“安全”,我们希望资源服务在锁的保护下能够做“正确”的事。更严谨的说,我们希望任一时刻,只有一个用户能够访问资源服务,而且即便锁在该用户在与资源服务交互的中途过期,也不至于破坏资源服务的一致性。
无论出于哪种目的,单从分布式锁服务的角度来说,我们都希望它具有如下属性(下文将以属性1,属性2,属性3来引用这些属性):
- 互斥(safety 属性):在任一时刻,只有一个用户能持有锁。
- 避免死锁(liveness 属性):每把锁都有一个有效期,超出有效期则自动释放锁。如果没有这样的自动释放机制,那么一个已获得锁的用户宕机或失联,将导致资源被持续锁定直至该用户故障被修复,在大部分场景中,这是不可接受的。
- 容错(liveness 属性):没有单点失败问题,只要系统中多数锁服务节点正常工作,用户就能够获取和释放锁。
下文讨论的 RedLock 算法期望解决的主要问题是单点 Redis 作为分布式锁服务时无法满足属性3,下面先来了解一下该算法。
Redlock 算法
Redlock 算法的实现基于单点分布式锁,下面是单个 Redis 实例实现分布式锁的方式。
首先是用户获取锁的命令1
SET key value NX PX 30000
这里 key 可能是某个你想锁的资源名,value 是某个全局唯一的随机值(该值后面会用于释放锁),这条命令在 key 不存在的前提下(NX选项),设置 key 对应的 value 值,30000 毫秒后,该 key 会过期(PX选项)。该命令执行成功则代表成功获取锁,否则代表已经有其它用户先获取了锁。下面是释放锁的代码1
2
3
4
5if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
如果你跟我一样看不懂 lua 脚本也没关系,这段代码的目的是比较 key(resource_name) 对应的 value 值是否是否等于之前设定的随机值,如果等于就删除该 key 来释放锁(注意该脚本的执行是符合原子性的)。之所以这么做是为了防止用户释放其它用户持有的锁(一个用户可能并不知道锁已经因为过期而被其它用户持有)。
这样单节点 Redis 服务器已经满足了属性1与属性2,但是该节点宕机将导致整个服务不可用,因此我们需要想办法进一步满足属性3。一个比较 naive 的做法是添加 redis 服务器做主从切换(failover),即 master 服务器不可用时自动将 slave 服务器晋升为 master。但这么做无法满足属性1,因为 Redis 主从数据复制是异步的,考虑下面的执行序列:
- 用户A在 master 服务器获取到锁。
- 在数据从 master 复制到 slave 之前,master 宕机。
- slave 成为新的 master。
- 用户B在新的 master 服务器获取到同一把锁,最终用户A与用户B持有相同的锁(违背属性1)。
下面来看看 Redlock 算法,假设我们有 N 个相互独立的 Redis 节点(这里先假设 N=5),用户按照下列操作来获取与释放锁:
- 获取当前时间戳
- 使用相同的 key, value 依次在所有节点上“获取锁”(方式跟之前在单节点上获取锁是一样的),每个节点获取锁的时间控制在一个比较小的范围内。举例来说,如果锁的有效时间是 10 秒,那么在每个节点获取锁的时间最好控制在 5-50 毫秒左右,这样才能保证如果某个 Redis 节点宕机或失联,整个获取锁操作不会阻塞太久。换句话说,如果单个锁服务实例不可用,尽快尝试在下一个实例获取锁。
- 用户计算步骤2所花费的时间(使用当前时间减去第一步保存的时间戳),当且仅当用户在多数锁服务节点(此例中3个节点)中成功获取到锁,并且获取锁花费的时间小于锁的过期时间,才算成功获取到锁。
- 如果步骤3获取锁成功,锁的实际有效时间是初始有效时间减去步骤2所花费的时间,比如锁的有效时间设定为 10 秒,步骤2花掉了 1 秒,那么锁的实际有效时间是 9 秒。
- 如果步骤3获取锁失败,尝试在所有节点上执行解锁操作(方式跟之前单节点上解锁是一样的)
以上基本就是 Redlock 算法的全部内容,相比单点 Redis 来说,它的作用是提供更高的可用性,即满足属性3。
争议点
在理解 Martin Kleppmann 与 Salvatore Sanfilippo 讨论的话题之前,需要先理解一些概念,这里我暂且把它们称作争议点。
1. Fencing Token
下图展示了一个失败的分布式锁的执行序列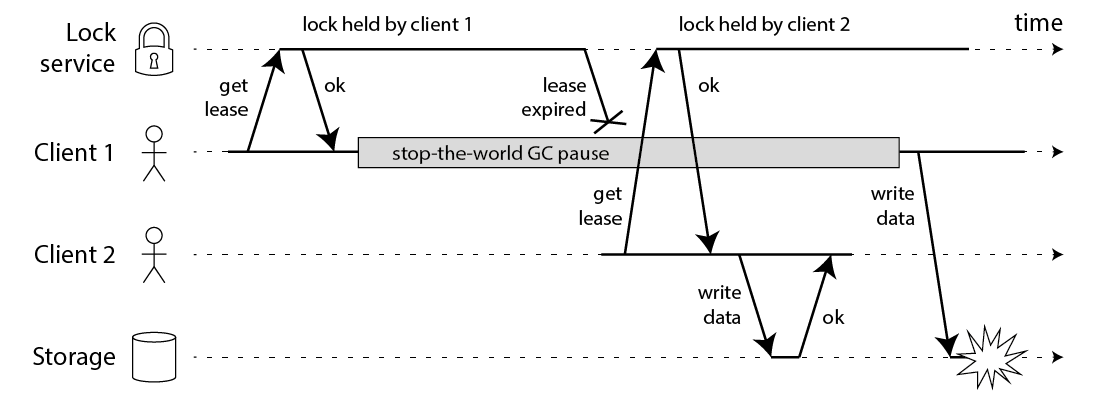
图中用户1在获取锁后进程暂停(导致进程暂停的原因可能有很多种,详情可以阅读 Kleppmann 的书或者该博客原文),在进程暂停期间,锁超时自动释放,于是用户2获得了锁,之后用户1从暂停中恢复。最终结果是用户1与用户2都认为自己拥有锁,资源服务也会同时受理用户1与用户2的请求,因此违背了属性1。
Kleppmann 建议使用一个全局单调递增的 "Fencing token" 来解决这样的问题。如图所示: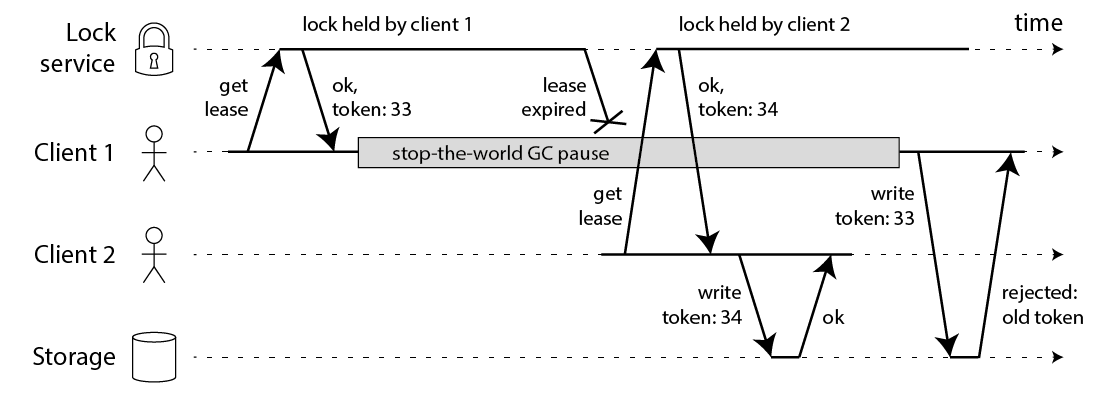
在每次用户获得锁时,锁服务同时为该用户分配一个全局单调递增的 token,我们要求每次用户请求资源服务时带上该 token。资源服务一旦受理过 token 值更高的请求,就拒绝其它 token 较低的请求。上图中用户1首先获得一个 token 为33的锁,之后进程暂停,锁超时自动释放,用户2获得 token 为34的锁。最后资源服务只受理用户2的请求。如果你使用 Zookeeper 作为分布式锁服务,它的 zxid 或者 znode version 都可以用来作为 "Fencing token".
2. Wall Clock 与 Monotonic Clock
现代计算机一般至少会提供两种时钟,分别是 Wall Clock 和 Monotonic Clock。
- Wall Clock(又称 Time of day clock, Real Time)
即 UNIX 系统中调用clock_gettime(CLOCK_REALTIME),JVM 中调用System.currentTimeMillies()得到的时间。该时间一般需要通过网络与 NTP(Network Time Protocol) 服务器同步,因此可能会突然跳到未来的某个时间点,或者跳回过去。而且它也可能被系统管理员手动设置,再加上还有闰秒问题。这些因素导致该时钟不适用于测量耗时。 - Monotonic Clock
即 UNIX 系统中调用clock_gettime(CLOCK_MONOTONIC),JVM 中调用System.nanoTime()得到的时间。正如它名字一样,该时间不会回退,同时它也不受 NTP 影响,因此非常适合测量时间区间。但单个 Monotonic Clock 时间值没有任何意义,比较不同电脑中的 Monotonic Clock 时间值也没意义。
3. Asynchronous System Model
在学术界,对于分布式算法来说,最理想的系统模型是 asynchronous model with unreliable failure detectors,该模型对时间不做任何假设,即进程可能暂停任意时间,网络中的包可能延迟任意久,时钟可能会任意跳跃。这些问题一般不会影响该模型下算法的 safety 属性,只有 liveness 属性才依赖于过期时间(timeout)或其它失败检测手段(failure detector)。换言之,就是在出现进程暂停,网络延迟,时钟跳跃等情况时,算法的性能可能毫无保障,但它至少不会做错误的决策。
Kleppmann 的质疑
- 关于 Fencing Token
Redlock 算法中并不存在任何机制用于生成全局单调递增的 token,它为锁提供的唯一随机数并不保证单调性。而简单使用一个 Redis 节点作为计数器又存在单点问题。在分布式系统中,你可能需要自己采用某种共识算法来生成这样的 token。 - 关于 Clock
Redis 使用 Wall Clock 而不是 Monotonic Clock 来判断 key 是否过期,这很容易导致 key 的过期比想象中快很多,或者慢很多。 关于算法对时间的依赖
Redlock 的 safety 属性过多的依赖于对时间的假设(Using time to solve consensus)。它假设所有的 Redis 节点持有 key 的时间约等于分布式锁的过期时间;假设网络延迟相比锁的有效期来说要小很多;假设进程暂停时间比锁的有效期小得多。
因此,如果时钟跳跃,Redlock 算法将无法满足属性1,假设锁服务由 A, B, C, D, E 五个 Redis 节点组成,考虑下面的执行序列(下文将以“示例1”来引用这个例子):- 用户1在节点 A, B, C 中获得锁,由于网络原因,D, E 节点不可达。
- C 节点时钟跳跃,锁在 C 节点中过期。
- 用户2在节点 C, D, E 中获得锁,由于网络原因,A, B 节点不可达。
- 用户1与用户2持有同一把锁(违背属性1)。
这个问题不止在时钟跳跃时会发生,如果节点C的 Redis 进程在将数据持久化到磁盘前被杀掉,然后立即重启(key 数据丢失),也有可能会发生同样的情况,因此 Redlock 文档中建议延迟节点的重启时间,使其至少与最长的锁有效期一样长。但是这种延迟重启策略再次依赖于节点C能够精准测量时间。
Kleppmann 在原文中还额外补充了另一个由进程暂停和网络延迟导致违背 safety 属性的例子(下文将以“示例2”来引用这个例子)。- 用户1在节点 A, B, C, D, E 请求锁。
- 当请求成功的响应还未返回到用户1时,用户1进程暂停。
- 锁过了有效期(A, B, C, D, E节点各自删除对应 key)。
- 用户2在节点 A, B, C, D, E 获得锁。
- 用户1从暂停中恢复,收到成功获得锁的信息。
- 用户1与用户2持有同一把锁(违背属性1)。
Sanfilippo 的回应
- 关于 Fencing Token
这个问题并不是 Redlock 独有的,还有很多带自动释放机制的分布式锁服务中都不提供单调递增的计数器。主要原因是:- 实现所谓的 "Fencing Token" 机制需要资源服务的积极配合。在分布式锁的大量使用场景里,我们没办法控制资源服务。如果我们有办法控制资源服务如何处理用户的请求,或许我们也不需要分布式锁了。
- 即便一定要 "Fencing Token",它也没必要是单调递增的,任何全局唯一 id 都可以用作 token。比如 Redlock 算法中每次申请锁时用的那个随机 value 值就可以用作 token。每次用户获取锁成功时,先设置资源服务的 currentToken,后续的每次请求都带上该 token,资源服务受理用户请求时如果发现 token 不一致就拒绝请求。简单说就是把
if (request.token < currentToken)改成if (request.token != currentToken)。同样可以保证同一时刻,只有一个用户允许访问资源服务。
- 关于 Clock(Redis 使用 Wall-Clock)
Sanfilippo 承认这是 Redis 的缺陷,并表示后续会修复这个问题。 关于算法对时间的依赖
根据 Kleppmann 的批评,Redlock 对时间的依赖主要包含三个部分:- 时钟依赖:所有的 Redis 节点持有 key 的时间需要约等于分布式锁的过期时间。
- 网络延迟依赖:网络延迟不能太高(相比锁的有效期来说)
- 进程暂停时间依赖:进程暂停时间不能太长(相比锁的有效期来说)
关于时钟依赖:Redlock 的 safety 属性并不依赖于各 Redis 节点的时钟是否有误差,而是依赖于各节点之间时间流逝的速度是否近似相等。比方说,各节点能将计时 5s 的误差控制在 10% 以内就行。影响这个误差的两个主要原因是:
- 系统管理员手动调整时钟
- ntpd 守护进程修改时钟(也就是前文说的 Wall Clock 同步网络时间的机制)
这两个问题都是可以避免的,问题1很简单,让管理员别这么做就行了。如果要考虑人为干预的话那管理员还可以
echo foo > /my/raft/log.bin来破坏 Raft 算法。问题2可以通过改用平滑修改时间的 ntpd 来避免。再说如果改用 Monotonic Clock。这两个问题也就都不存在了。
关于网络延迟依赖:Redlock 算法在步骤三会计算获取锁用掉的时间,如果有包括网络延迟在内的任何原因导致获取锁用掉的时间多于锁的有效时间,则获取锁失败。所以网络延迟不会影响算法的 safety 属性。
关于进程暂停时间依赖:进程暂停如果发生在算法的步骤三之前,那它造成的影响等同于网络延迟,最终只可能导致获取锁失败。如果发生在步骤三之后(即用户认为自己获取锁成功之后),那结果等同于争议点一(Fencing Token)的执行序列。
我对分歧的看法
(个人认为)两篇文章表达的分歧有:
- 分歧1:Kleppmann 认为安全的分布式锁服务需要同时提供一个全局递增的 token。Sanfilippo 由于资源服务常常不可控,因此该 token 没必要
- 分歧2:即使 "Fencing Token" 有必要,出于 "Fencing" 的目的,全局唯一与全局递增也没什么区别。
- 分歧3:Kleppmann 认为 Redlock 的安全性过多的依赖于对时间的假设(参见示例1与示例2)。Sanfilippo 并不赞同,因为示例2中网络延迟与进程暂停如果发生在算法的步骤三之前,则问题并不存在,如果发生在步骤三之后,则等价于 Fencing Token 问题(这里我没看到关于示例1的解释,但个人觉得示例1依然等价于 Fencing Token 问题,原因后面会提到)。
这些分歧其实都出于对属性1的描述(在任意时刻,只有一个用户能持有锁)不够严谨。假设有 A, B 两个用户,针对同一资源,我们理想中的属性1应该进一步拆分成如下属性:
- 属性a: 在任意时刻,锁服务都知道自己是否已授权锁,如果已授权,锁服务知道具体授权给了哪个用户(这里假设授权给了用户A)。
- 属性b: 在任意时刻,最多只有一个用户认为自己获得了锁。
- 属性c: 在任意时刻,资源服务最多只允许一个用户访问。
- 属性d: 在任意时刻,如果锁已授权给一个用户,资源服务只允许当前锁服务授权的那个用户访问(用户A)。
首先我们可以确定的是,在异步系统模型,锁会自动释放的前提下,可以得到:
结论1:属性b不可能满足。
证明:在不对时间做任何假设的情况下,用户以为自己持有锁,但锁已经过期,这种情况是无法避免的,参见"Fencing Token"中的第一个例子与示例2。
现在不妨先来看分歧3,包括 Sanfilippo 自己也认为 Redlock 的正确性依赖于所有 Redis 节点中,时间以接近的速度流逝。但我认为并非如此,因为如果现实并不满足这条假设,那么算法只是无法满足属性b(注意这里无所谓算法是否可以满足属性b,因为反正结论1告诉我们属性b不可能满足),但该算法依然保证了属性a。在示例1中,c节点发生时钟跳跃,最终导致的结果其实等价于锁提前过期,在时钟不可靠的情况下,锁提前或延后过期总会发生,这对属性a而言并没有影响。换言之即使使用单节点 Redis 锁,该节点时钟同样可能发生跳跃,锁同样可能提前过期。因此示例1的问题同样等价于 "Fencing Token" 中的问题,它们本质上都是锁用户并不知道自己持有的锁已经过期的问题。即便你的锁不设有效期,而是使用 Zookeeper 临时节点,通过 Zookeeper session(对用户做心跳验证) 来判断锁是否过期,该问题依旧存在。
同时,基于结论1,我们可以得到:
结论2:如果资源服务不可控,属性c也不可能满足。
证明:由于属性b无法满足,势必会出现某个时刻,两个用户同时认为自己拥有锁,而此时如果资源服务不受控(即无法使用Fencing Token),则属性c无法满足。
这样一来分歧1可以用一句话概括,是否需要 "Fencing Token" 取决于你的系统是否需要满足属性c,换句话说,如果你的目的是 Efficiency,则 Redlock 算法和其它分布式锁机制一样,是“安全”的。如果你的目的是 Correctness,则 Redlock 是不“安全”的。
最后是分歧2,出于 "fencing" 的目的,全局唯一的 token 是否等价于全局递增的 token?假设我们照 Sanfilippo 所言在资源服务中使用全局唯一的 token 验证用户是否真的持有锁,考虑下面的执行序列:
- 用户A获得锁后,进程暂停,锁过期。
- 用户B获得锁后,将资源服务的 currentToken 设成 B.token。
- 用户A从暂停中恢复,将资源服务的当前 currentToken 设成 A.token。
- 锁服务认为 B 持有锁,但资源服务认为 A 持有锁(满足属性c,不满足属性d)。
这样看来,使用全局递增的 token 就能解决这个问题,但再考虑下面的执行序列:
- 用户A获得锁后,进程暂停,锁过期。
- 用户B获得锁后,进程暂停。
- 用户A从暂停中恢复,继续访问资源服务。
- 锁服务认为 B 持有锁,但直到用户 B 与资源服务通话之前,资源服务都认为 A 持有锁(满足属性c,不满足属性d)。
这里的结论是,全局唯一与全局递增的 token 都只能满足属性c,无法满足属性d,但如果使用递增 token,资源服务能够在收到 B 的请求后,第一时间意识到 B 是较近的一个持有锁的用户。所以(个人认为)如果仅仅从对资源的“排它”访问这一角度考虑,这里 token 的全局唯一确实等价于全局递增,但总的来说,全局递增更倾向于将交互权授予较新的锁持有者。
Correctness 还是 Efficiency?
看到这里,很容易产生一个误区,认为只要满足属性c,就能实现 Correctness。但事情没那么简单。假设我们的资源服务是某种 collection,对外提供添加元素与自增 size 的接口。我们希望使用分布式锁与 "Fencing Token" 机制来保证 collection 中元素数量与 size 属性的一致性。下面是一个可能的用户代码片段:1
2
3
4int token = distributedLock.lock(collection, 1000 * 10); // 锁的有效期为10秒
collection.add(token, element);
collection.incrementSize(token);
distributedLock.unlock(token);
该代码显然无法达成目的,考虑下面的执行序列:
- 用户1获取一个 token 为 33 的锁,执行
add添加元素,进程暂停,锁过期。 - 用户2获取一个 token 为 34 的锁,执行
add与incrementSize成功。 - 用户1进程恢复,以为自己依然拥有锁,试图执行
incrementSize。 - 资源服务已经受理过 token=34 的请求,因此拒绝用户1请求,元素数量与 size 属性的一致性被破坏。
通过分析这个例子,可以得出的结论是属性c依然无法满足 Correctness 需求,我们还需要:
属性c':在任意时刻切换用户不会破坏资源服务的一致性。
为了满足属性c',collection 服务至少有两种解决方案:
- 方案一:像传统数据库对事务的处理那样,添加一个 commit, rollback 机制,如果在收到某个用户的 commit 请求之前发生了用户切换,rollback 该用户的所有操作。(这种方案需要某种机制来区分不同的用户,或者说不同的“事务”)
- 方案二:将 add 与 incrementSize 合并成一个原子操作。
假设我们选择方案二,那么资源服务本身已经支持并发访问了,引入分布式锁服务只会降低整个系统的效率。假设我们选择方案一,那么分布式锁在这里的作用只是减少 rollback 的发生频率,即使不用 Fencing Token,最多也只是导致 rollback 发生得更频繁一点。更有甚者,即使不用锁,多个用户并发访问资源服务,导致资源服务频繁 rollback,没有任何一个用户能执行到 commit 逻辑,这也不会影响到资源服务数据的一致性。换句话说,这里使用分布式锁的目的已经不再是 Correctness,而是 Efficiency 了。
结论
尽管 HN 上大多数人都站在 Kleppmann 这边,认为 Redlock 只能用于 Efficiency 而不是 Correctness。但目前为止,我更偏向于支持 Sanfilippo,正如它文中提到的那样
"Most of the times when you need a distributed lock system that can guarantee mutual exclusivity, when this property is violated you already lost. Distributed locks are very useful exactly when we have no other control in the shared resource."
更进一步,我认为所有带自动释放机制的分布式锁,本质上只是在为系统提供 Efficiency, 而 Correctness 需要资源服务自身通过某种机制(原子操作或事务日志等等)来保证。