随便写写跟事务相关的笔记
ACID
原子性(Atomicity)
这里的原子性含义与多线程编程中的原子性有一些细微的区别,在多线程语境中,如果一个方法满足原子性,则其它线程无法看到该方法执行的中间状态,但它并不保证该方法中的语句全生效或全不生效(All or Nothing)。相反,ACID 中的原子性保证 All or Nothing,但其并不保证其它事务是否能看到该事务执行的中间状态,在 ACID 中,该属性由隔离性(Isolation)来保证。考虑下面这段程序1
2
3
4
5
6
7
8
9
10
11
12
13
14var counter: Int = 0;
fun increase() {
counter++;
if (ThreadLocalRandom.current().nextBoolean())
throw Exception("Oops!")
counter++;
}
fun printCurrent() {
println(counter);
}
这里 @Synchronized 保证 increase 方法是符合原子性的,这意味着,如果没有异常出现,则 printCurrent 方法不可能打印出一个奇数。但如果出现异常,counter 的第一次自增并不会回滚,也就是说这次 increase 调用只将 counter 自增1。与其相对的是下面这段 SQL 代码:1
2
3
4
5
6
7
8begin transaction;
update counter set value = value + 1 where id = 1;
if ROUND(RAND(),0)=1
begin;
THROW 50000, 'Oops!', 1
end;
update counter set value = value + 1 where id = 1;
commit;
即便没有异常出现,如果没有 Isolation(或者 Isolation.level = READ_UNCOMMMITTED),则其它事务能看到这段代码的中间状态,但如果有异常出现,第一次自增的操作会被回滚。
从这个角度来说,ACID 中的 Atomicity 更多的指的是在错误出现时能够自动撤销之前修改,也许把 "A" 理解成 Abortability 更恰当。
一致性(Consistency)
ACID 中的一致性,表示事务只会将数据从一种“正确”的状态修改成另一种“正确”的状态。举例来说如果说有一个用户交易系统,所有的事务只会把金额从一个账户转移到另一个账户,那么可以保证的是无论执行多少次转账交易,该系统所有账户的余额都是“正确”的。
这里的“正确”之所以要打引号是因为它是由应用定义的,除了一些外键约束,唯一约束之外,数据库并不能理解当前的数据是否符合你对“正确”的定义。
换句话说,原子性,隔离性,持久性是数据库的属性,但一致性可能更应该被看成应用的属性,应用通过数据库提供的原子性,隔离性来保证数据的一致性。因此 "C" 并不真的属于 “ACID”(It was said that the C in ACID was "tossed in to make the acronym work")。
隔离性(Isolation)
隔离性意味着并发执行的事务应该相互隔离,换句话说,即便在现实中会有大量事务并发执行,数据库系统应该保证这些并发事务执行结果跟按时间顺序一个接一个执行的结果是一样的,很容易想到这是一个需要牺牲性能才能满足的属性,因此大部分数据库产品会提供一些较“弱”的隔离级别供用户选择。
持久性(Durability)
持久性意味着一旦事务执行成功,其带来的修改不会丢失,单从字面上看,这其实是一个无法实际达成的属性,因此这里可以将其理解成,一旦事务执行成功,意味着其修改已被写入某种永久存储介质(比如硬盘),类似于进程被终止或停电等问题不会造成数据丢失。
反常现象与隔离级别(Anomalies and Isolation Level)
在现实中,并发与竞争条件往往处理起来非常复杂,且容易出错。因此数据库产品希望通过 Isolation 将这部分复杂的逻辑转移至存储引擎(就像 JDK 要实现线程安全的集合一样),然而正如前文所提到的那样,实现完整的 Isolation 对数据库的性能影响过大,所以数据库一般会提供一些“弱”隔离级别(Isolation Level),并注明在这些隔离级别下,会出现哪些可能的反常现象(不幸的是,这些反常现象,隔离级别以及对应的实现在数据库领域并没有很好的标准化。也就是说不同的隔离级别在不同的数据库产品中可能有不同的叫法,它们能够防止的异常现象也可能不一样,下文的内容只能够作为参考)。
脏写(Dirty Write)
假设我们有一个在线买车的应用,买车操作涉及两个步骤,首先在 listing 表中更新指定车的买家,之后在 invoices 表中更新发票的接收者,下面的例子中,Alice 与 Bob 同时购买同一辆车。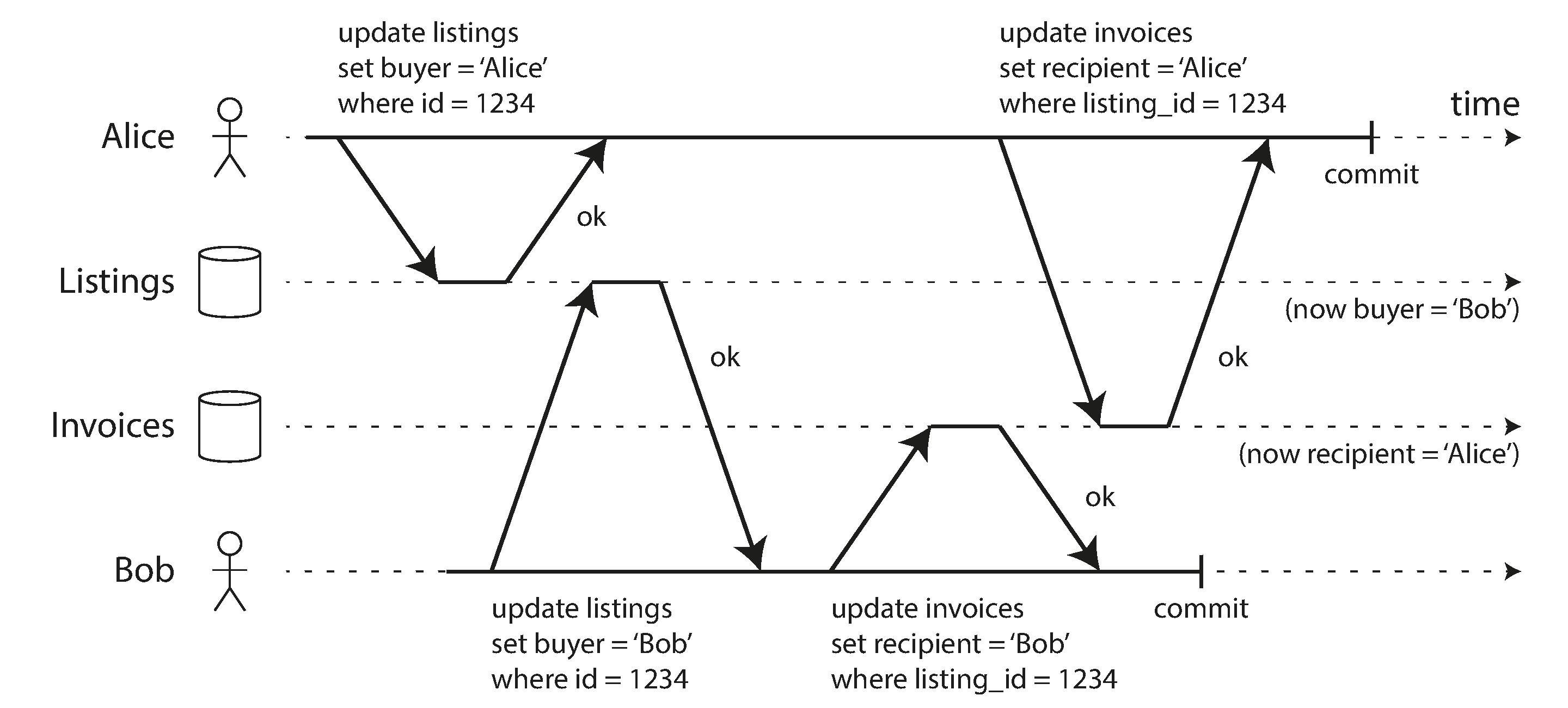
由于 Alice 更新 listing 表的操作被 Bob 覆盖,Bob 更新 invoices 表的操作被 Alice 覆盖,最终导致的结果是 Bob 是车的买家,但 Alice 成了发票的接收人。这种现象被称为脏写(注意区分脏写与下文提到的丢失更新现象,脏写是覆盖未提交的修改,丢失更新是覆盖已提交的修改)。
大部分数据库通过行级锁(row-level lock)来防止脏写,如果一个事务想要修改一条记录,首先需要获取锁,并一直持有锁直到事务最终提交或回滚,如果其它事务想要修改同一行,则修改必须阻塞直到它能够获取到锁为止(注意这种方式并不能防止丢失更新)。
脏读(Dirty Read)
如果一个事务可以读取到其它事务未提交的修改(即其它事务执行的中间状态),也就违反了上面多线程语境中的 Atomicity(更糟糕的是,由于事务的 Abortability,你可能会读到其它事务已经回滚的修改),这种现象被称为脏读。
脏读也可以通过同样的行级锁机制来避免,即要求事务在读取行数据时先获取锁,读取完再释放,这样可以保证如果某行数据被某个事务修改,在该事务释放锁之前其它事务都无法读取到该行数据(IBM DB2使用这种方式)。但大部分数据库产品不这么做,而是在行数据被修改时,维持该行数据修改前后的两个副本。当没有锁的事务读取时,返回修改前的版本,当持有锁的事务读取时,返回修改后的版本。
不可重复读(Nonrepeatable Read/Read Skew)
假设我们有一个银行系统,Alice 有两个账户,分别存了500块钱,Alice 试图将100快钱从账户2转移至账户1,并在转账的同时分别查询两个账户的余额,它可能会看到如下情况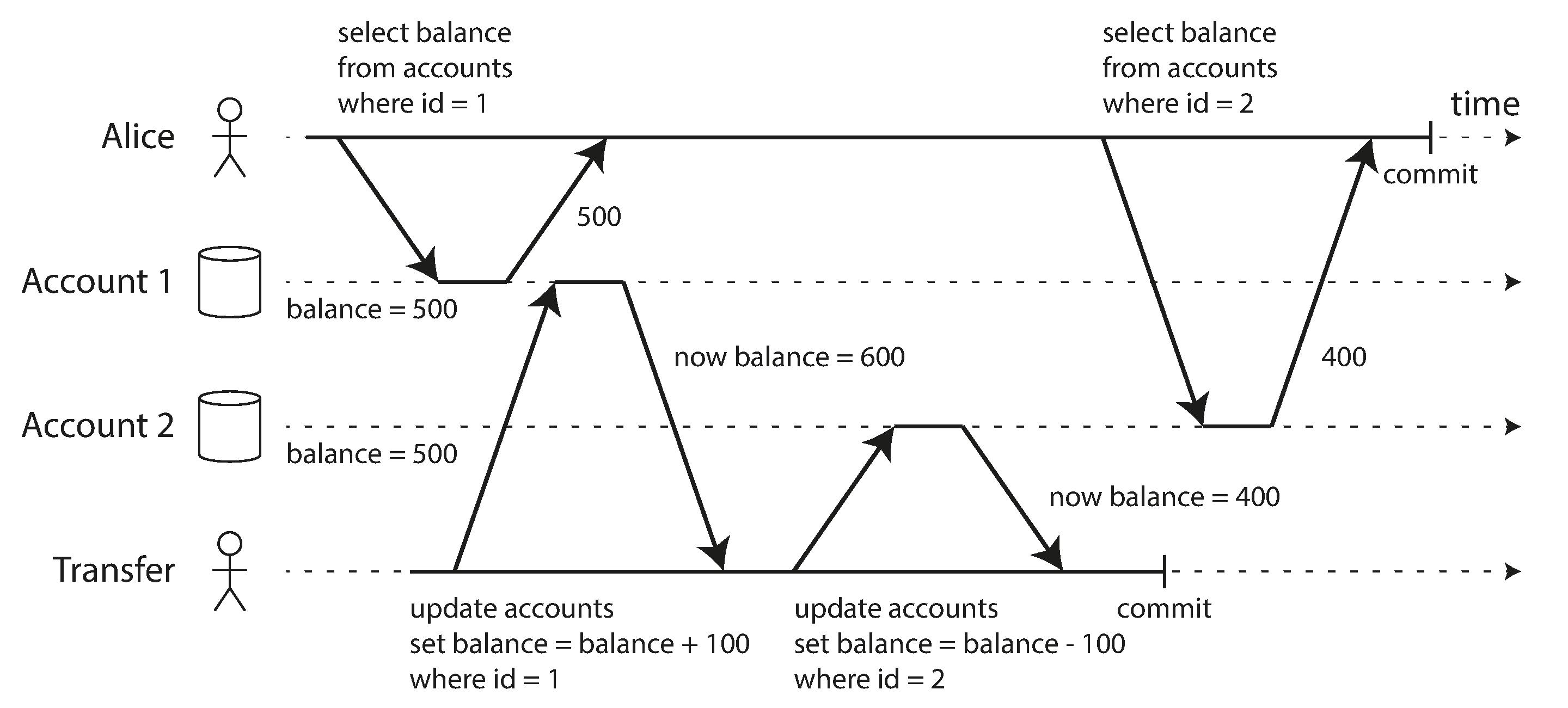
Alice 的查询事务先查询账户1,发现余额是500元,再查询账户2,发现余额是400元,资金总和成了900元,这会让人产生迷惑(这里如果它最后在同一事务中再次查询账户1,会得到余额600元)。同一个事务中,两次读取同一条数据返回结果却不一样。这种现象称为不可重复读(或读偏移)。
大部分数据库产品采用快照隔离来实现可重复读,其核心原则是读取不阻塞写入,写入也不阻塞读取,它的实现思路与之前通过保持数据修改前,修改后的版本来防止脏读类似。不同的是之前只需要维护行数据的两个版本(即已提交的版本与已修改但未提交的版本),但实现快照隔离则需要维护行数据的多个版本,这种方法又称为多版本并发控制(multiversion concurrency control)。
一般来说如果一个存储引擎实现了快照隔离,它也可以复用这些快照来实现提交读隔离级别,如果当前事务是提交读隔离级别,则每次查询同一行数据有可能返回不同的快照,但如果是可重复读隔离级别,则每次查询只返回同一快照。
下图演示了 PostgreSQL 中实现快照隔离的大致方案,当一个事务开始时,为其分配一个全局单调递增的事务id,如果该事务对数据做出了修改,被修改的数据将同时保存该事务id: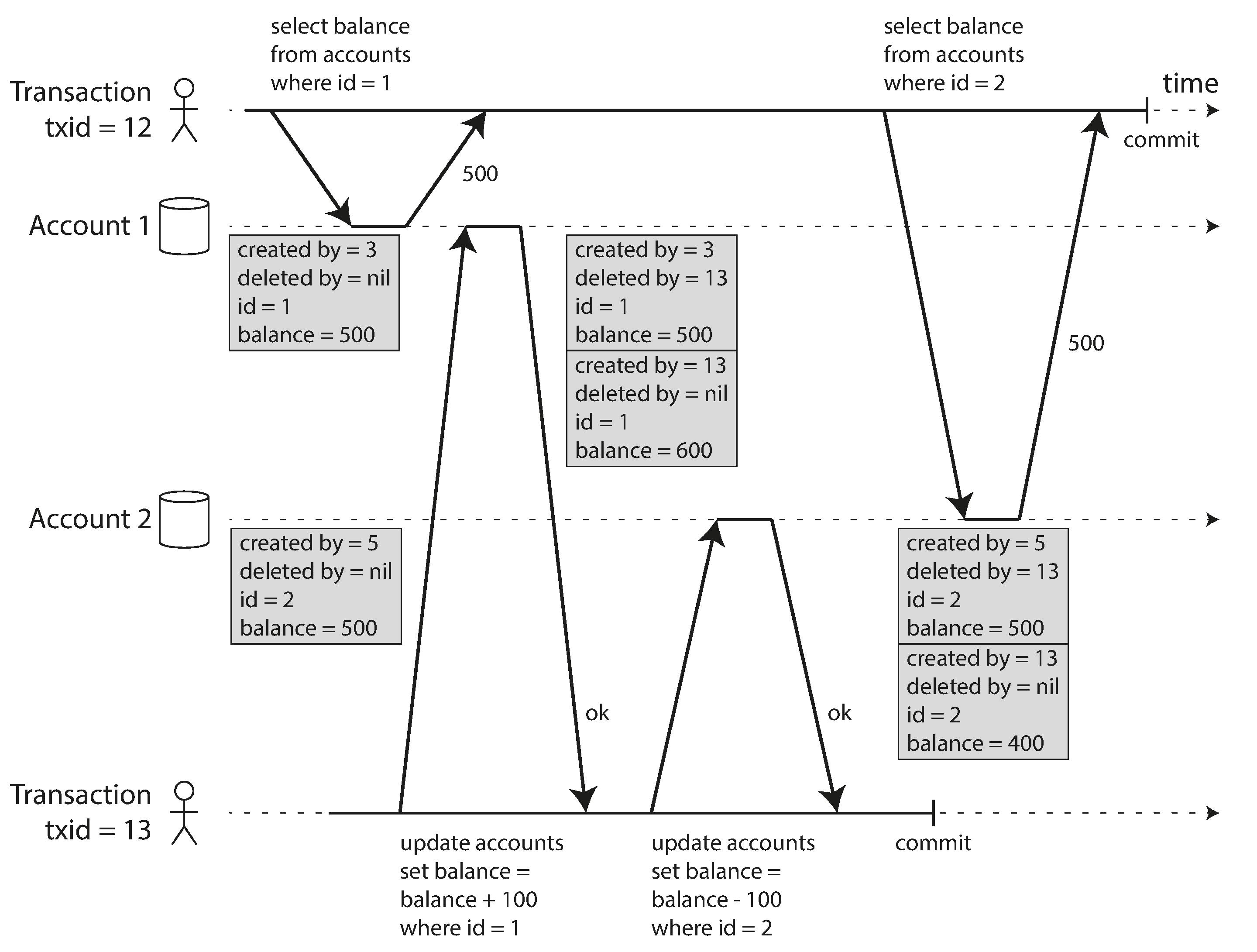
表中的每条行数据都有 create_by 与 delete_by 两个字段,分别记录了插入事务与删除事务的事务id,具体的实现方式如下:
- 新增
在 create_by 字段记录创建者的事务id。 - 删除
在 delete_by 字段记录删除者的事务id。之后当垃圾回收机制确认没有任何事务能够访问到该行数据时,再将其真正清除。 - 修改
将修改转化成删除与创建,举例来说,事务13从账户2将账户2的余额从500改成了400,现在账户2在账户表中存在两条记录,一条余额为500,被标记为 deleted by tx13,另一条余额为400,被标记为 created by tx13。 查询
查询按如下方式工作:- 在事务开始时,数据库为其生成一个列表,记录其它正在进行中的事务,忽略由这些事务做出的任何修改。
- 忽略任何 aborted 的事务的修改(即忽略所有回滚的事务修改)。
- 忽略任何事务id大于当前事务所做出的修改。
- 剩下的其它修改对查询可见。
换句话说,数据仅当满足如下条件才可见:
- 在查询事务开始时,创建该数据的事务已提交。
- 数据没有被标记成删除,或已被标记为删除,但在查询事务开始时,将其标记为删除的事务还没有提交。
快照隔离是很常用的隔离级别,但在不同的数据库可能有不同的叫法,Oracle 中称其为 serializable,PostgreSQL 和 MySQL 称其为 repeatable read。在 IBM DB2 中使用 repeatable read 来指代 serializability,最终导致没有人知道 repeatable read 到底指的是哪种隔离级别。
丢失更新(Lost Updates)
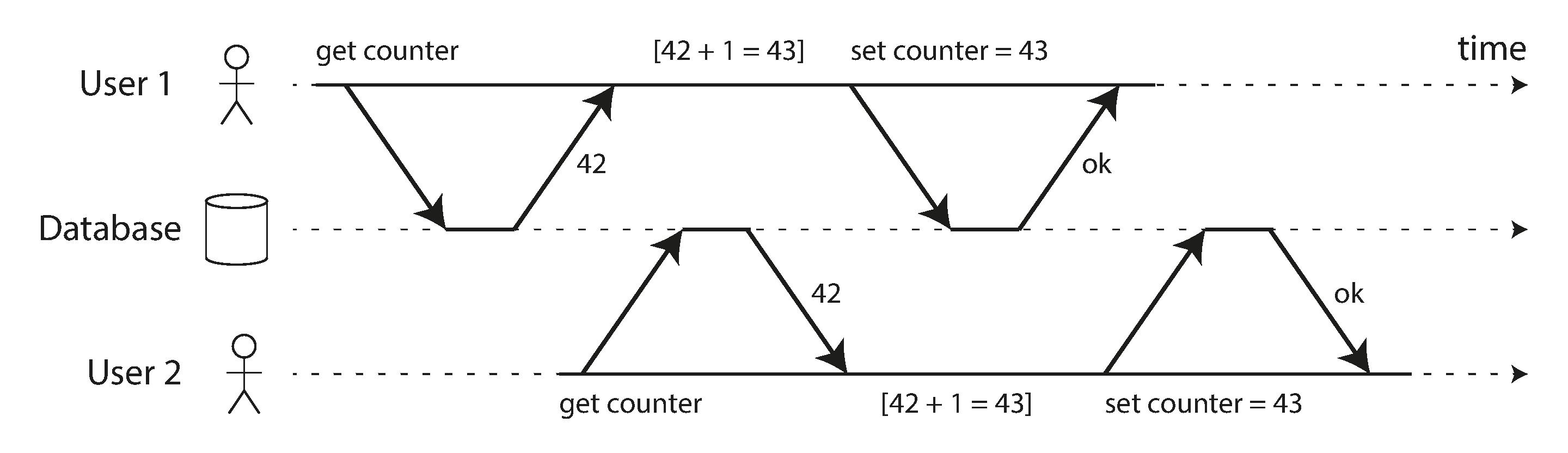
即当两个事务并发的执行读取-修改-写入时,其中一个事务做出的修改并另一个事务覆盖。
- 原子操作
如果读取-修改-写入符合原子性(注意这里指的是并发编程中的 Atomicity 而不是 ACID 中的 "Abortability"),那么其它事务无法看到该流程的中间状态,也就是说不会发生丢失更新。大部分数据库保证如下 SQL 语句是符合原子性的但是这种方式有个非常明显的缺点,如果你需要先读取数据,执行一些检查逻辑,最后再决定要不要 increase,这种方法就不适用了。1
update counters set value = value + 1 where key = 'foo';
- 显式排它锁(悲观锁)
之前讨论如何防止脏写现象时提到过行级锁,在事务更新行数据时需要先获取锁,之后持有该锁直至事务最终提交或回滚。这种方式只能防止脏写,无法防止丢失更新,因为它只阻塞其它事务的写操作,不阻塞读操作。因此我们可以显式使用 for update 语句来为行数据添加排它锁,该锁会阻塞其它事务的读操作( 注意,其它事务必须也使用 select ... for update 语句读,换句话说,select for update 阻塞 update 与其它 select for update,但不阻塞 select ),从而达到防止丢失更新的目的。1
2
3
4
5begin transaction;
select value from counters where key = 'foo' for update;
-- some logic
update counters set value = value + 1 where key = 'foo';
commit; - Compare-and-set(乐观锁)
CAS 是并发编程中一种非常常见的用于防止丢失更新的方式,大致的方案见如下代码注意上面代码中的 where 条件增加了1
2
3
4
5begin transaction;
select value from counters where key = 'foo';
-- some logic
update counters set value = value + 1 where key = 'foo' and value = oldvalue
commit;value=oldvalue,如果有其它用户在该事务执行中途修改了 counter 值,则该事务将执行失败,对比悲观锁使用阻塞,乐观锁使用的失败+重试来达成防止丢失更新的目的。这里值得注意的一点是,考虑到某些数据库产品对快照隔离的具体实现,where 从句可能会读到事务开始时的快照,也就意味着value=oldvalue可能恒成立,这种方法就失去效果了。 - 自动探测丢失更新
如果数据库实现了快照隔离,丢失更新现象很容易被自动探测到。PostgreSQL 的 repeatable read, Oracle 的 serailizable 和 SQLSever 的 snapshot isolation 都会自动探测丢失更新并终止事务,需要注意的是 MySQL 的 repeatable read 隔离级别不会探测丢失更新,因此有人认为 MySQL 并没有真正提供快照隔离。
幻读(Phantom Read/Write Skew)
假设我们实现了一个医院的排班系统,医生允许通过该应用请假,但需要保证在任意时刻至少有一名医生在值班。我们实现请假的思路是先检查当前正在值班的人数,只有在人数大于等于2的前提下才允许医生请假。现在假设 Alice 和 Bob 正在值班,它们都想请假,并几乎同时在应用中按下了请假按钮,下图展示了可能发生的事: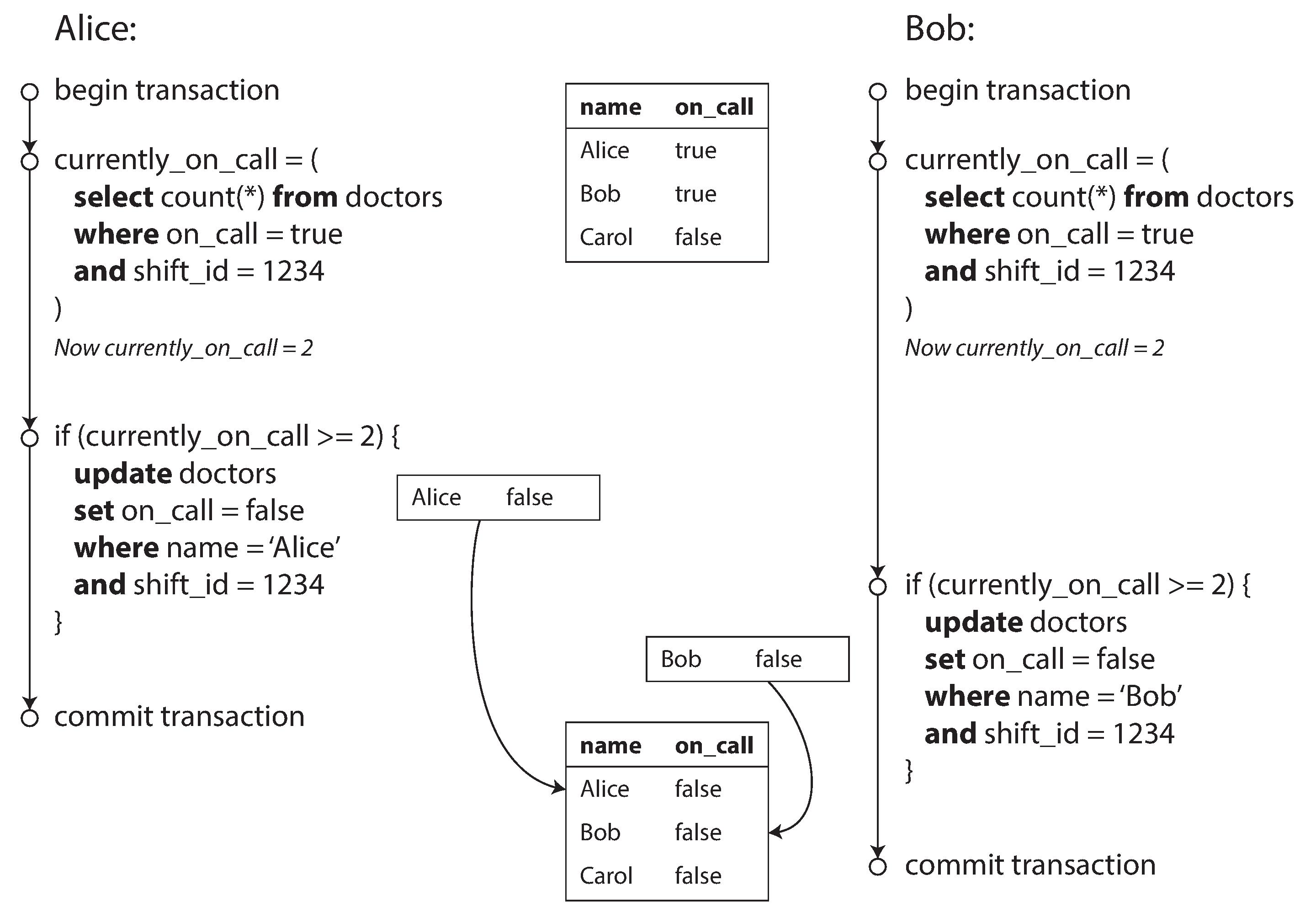
由于 Alice 与 Bob 几乎在同时请求当班人数,该请求都返回2,于是两个人同时通过了该约束,进入应用代码的下一阶段,最后结果是两个人都请假成功,导致无人值班,这种现象称为写偏移(write skew)。下面是另外两个常见的例子:
- 房间/机票预定系统
假设我们希望保证一个房间不被多个用户同时预定,可能的流程如下同样,多个事务并发执行时,快照隔离无法保证不会有多个用户在同一时段预定该房间。1
2
3
4
5
6begin transaction;
select count(*) from bookings where room_id=123
and end_time > t1 and start_time < t2;
-- check if the query return zero
insert into bookings values (123, t1, t2, user_id);
commit; - 注册用户
在用户注册时,我们可能希望用户名是唯一的,如果你在应用层做唯一检查,那么快照隔离级别无法保证最终用户名的唯一性。(好在大部分数据库提供唯一约束来实现该目的)
上面所有的例子基本上都有着类似的模式:
- 用户先执行 select 语句,然后判断执行结果是否满足一些特定条件(比如说查询某时段值班人数,某时段房间的预定记录,某用户名是否存在)。
- 基于第一次查询结果来执行一些操作。
- 第二步执行的操作会影响到第一步的查询结果。
进一步可以发现,这些现象发生的根本原因是因为在一个事务中所做出的修改,可能改变另一个事务中某条 select 语句的查询结果,这种现象又被称为幻读(同一个事务中,多次执行同样的查询可能得到不同的结果集)。
冲突具体化(Materializing Conflicts)
在排班系统中,第三步针对第一步返回的结果集做 update 操作,因此我们可以通过在第一步中使用 select for update 排它锁来避免写偏移。但在其它例子中,我们的判定结果依赖于第一步返回空集合,即第三步针对第一步返回的结果集做 insert 操作,在这种场景下,我们没有行记录可以加锁,为了找到合适于加锁的行对象,我们可以让冲突具体化,举例来说,在预定房间的例子中,我们可以为每个可能的房间 + 预定时段组合生成一条记录,这样我们就可以通过 select for update 语句甚至于乐观锁来保证不会发生冲突(如果你觉得生成这样的记录太麻烦,也可以降级到只锁预定时段或房间记录,锁的粒度越大则系统的效率越低,你甚至可以只锁一条 isBooking 的记录来实现同步,本质上来说这就跟用数据库实现分布式锁没什么区别了)。
这么做的缺点是需要应用代码的介入,而且细粒度的控制可能会非常麻烦(比如说你需要定时预生成针对每个房间未来一段时间的预定记录),因此在性能允许的情况下,更推荐使用串行化隔离级别来解决这个问题(注意这里并不是让你将数据库默认的隔离级别设置成串行化,而是只针对特定事务将其设为串行化)。
串行化(Serializability)
串行化被认为是最“严格”的隔离级别,它保证即使事务是并发执行的,但其执行结果跟按时间顺序一个接一个执行的结果是一样的。换句话说,如果你使用该隔离级别,那么前面所有由并发,竞争条件所带来的问题都不需要考虑了。下面简单介绍一些串行化的实现方法。
按顺序执行(Actual Serial Execution)
最直观的方法就是真的在存储引擎中使用单线程按顺序执行事务,尽管这种方法很明显,但人们直到 2007 年左右才开始意识到这是一种可行的方法,导致大家重新重视这种方法的原因主要有两个:
- 随着内存降价,将整个数据集放入内存中已经称为可行的方案,如果整个数据集都在内存中,那么事务的执行会比以前快很多。
- 数据库设计者开始意识到 OLTP 事务一般持续时间不会太长,也不会做太多的读取和写入。而 OLAP 事务一般是只读的,因此它们可以在多线程环境下使用快照隔离级别执行。
这种方法的核心依赖在于每个事务必须能够快速执行,在传统的事务中,应用服务器与数据库服务器需要产生多次交互(发送查询命令,接收查询结果等),一个事务执行大部分时间都花在网络 IO 中。如果让数据库服务器单线程执行这样的事务,其性能可想而知。因此,如果要单线程串行执行事务,一般会让应用服务器以存储过程的形式将整个事务逻辑一次性发送至数据库服务器,这样一来就不用花时间等待网络与磁盘 IO 了。但依赖于存储过程也就成了这种方法最大的缺点,毕竟应该没有程序员喜欢写存储过程吧,其次,如果一个事务需要涉及到多个数据分区,这种方法的性能也会受到严重影响。
注:目前使用顺序执行的数据库有 Redis, Datomic。
二阶段锁(Two-Phase Locking)
二阶段锁类似于之前用于防止脏写现象的行级锁,只不过比之前更加严格:
- 如果事务 A 已经读取了行数据,事务 B 想要修改这行数据,则事务 B 需要阻塞直到事务 A 提交或终止。
- 如果事务 A 修改了一行数据,事务 B 想要读取该行数据,则事务 B 需要阻塞直到事务 A 提交或终止(而不是读取一个 A 的快照)。
之前我们提到过快照隔离的核心原则是读取不阻塞写入,写入也不阻塞读取。相比之下,二阶段锁则更像并发编程语境中的写锁(排它锁)与读锁(共享锁),每个行锁都有排它与共享两种模式:
- 如果一个事务想要读取一条记录,必须先获取该条记录的读锁。
- 如果一个事务想要修改一条记录,必须先获取该条记录的写锁。
- 如果一个事务先读取,再修改一条记录,则需要将它的读锁升级成写锁。
- 如果一个事务获取了锁,则必须持有锁直至事务提交或终止(让人有点迷惑的是,二阶段锁的名字出自这里,第一阶段是事务运行阶段,第二阶段是事务终止阶段)。
(注意:由于大量使用锁机制,因此该实现很容易出现死锁,数据库必须能够自动检测死锁并终止其中一个造成死锁的事务)
细心的同学可能会发现,二阶段锁依然没有解决之前由于幻读造成的写倾斜问题。为此我们还需要引入断言锁(Predicate Locks)的概念,即我们不仅需要对行对象加锁,还需要对未来可能出现的行对象加锁,拿之前预定房间的例子来说:1
2select * from bookings
where room_id=123 and end_time > t1 and start_time < t2;
我们需要对上面 where 从句匹配的整个区域加锁,即便该区域目前可能没有记录。
断言锁与行级锁的工作方式类似,即
- 如果事务 A 想要读取匹配指定条件的所有记录,需要先获取该条件的读锁。
- 如果事务 A 想要插入,修改,删除一条记录,需要先检查修改前与修改后的记录是否跟匹配某个条件锁,如果是的话,事务 A 需要获取该条件的写锁。
可以看到这种方法需要对大量的写操作做条件匹配运算,因此并不实用,大部分数据库采用的是一种近似的实现方法,也就是索引区域锁(Index-range Locks),以上面的查询条件 where room_id=123 and end_time > t1 and start_time < t2 来说,该查询涉及到三个索引,分别是 room_id, start_time, end_time:
- 假设数据库使用 room_id 作为第一索引来执行查询,可以直接在 room_id=123 索引上加共享锁,该锁预示有一个事务正在查询房间123的所有预定记录。
- 假设数据库先使用 start_time 和 end_time 索引执行查询,则可以直接锁一个索引区域,预示有一个事务在查询该时间段的预定记录。
换句话说,索引区域锁通过锁定一个大于等于断言锁的区域来避免多次进行条件匹配运算,如果实在没有合适的索引可以用来加锁,则数据库可以直接对整张表加锁。
注:目前使用二阶段锁的数据库有 MySQL(InnoDB), SQLServer。
串行快照隔离(Serializable Snapshot Isolation(SSI))
之前在讨论如何防止丢失更新时我们已经讨论过悲观锁与乐观锁,悲观并发控制的思路是,如果两个操作并发执行有可能会出错,那么假设它一定会出错,因此需要阻塞其中一个操作。相反,乐观并发控制的思路是假设并发执行一定不会出错,在事务最终提交前,再通过某种机制来检查是否有错。换句话说,悲观并发控制更倾向于阻塞,乐观并发控制倾向于失败与重试。从防止幻读这个角度来说,按顺序执行与二阶段锁都是采用悲观并发控制的思路,而串行快照隔离则采用乐观并发控制思路,下面简单介绍它的实现思路。
从之幻读的例子中,我们可以总结出一种模式,即一个事务先查询某些记录,然后依据该查询结果决定后续的操作,在快照隔离级别下,等到事务提交时,这个查询结果可能已经被其它事务修改了。因此,一旦数据库探测到某个事务的某次查询结果已经被其它事务修改了,则该事务后续的所有写请求可能都是不安全的,数据库必须阻止该事务提交。剩下的问题在于如何探测这些“过期”的查询(stale reads)。下面简单介绍快照隔离下,可能出现过期查询的情况以及串行快照的处理方式:
- 在读取之前,存在其它事务未提交的修改,依据快照隔离的实现,这种情况查询的结果可能是已过期的快照。
为了防止这种情况发生,我们需要去跟踪并收集那些依据 MVCC 可见规则而忽略掉的修改的事务 id,最后在事务提交时,检查这些事务 id 中是否有成功提交的事务,如果有则终止当前事务。 - 在读取之后,其它事务修改数据并提交。
在之前介绍二阶段锁时我们提到过索引锁,即在事务读取某个索引区域的时候,先获取该索引区域的读锁,并阻塞其它试图修改该索引段的事务。这里我们可以采取类似的机制,但我们只记录哪些事务读过该索引区域,当有事务试图修改该索引区域时,并不阻塞该事务,而是通知之前读取过该索引段的事务它们可能读到了过期数据。
相比其它两种实现,这种方法最大的优势在于读取不会阻塞写入,最大的缺点在于,一个事务涉及的语句越多,执行的时间越长,就越有可能遇到冲突而回滚,换句话说,在高并发环境下,一个耗时较长的事务可能一直无法提交成功。
注:目前使用 SSI 的数据库有 PostgreSQL(since version 9.1), FoundationDB。
轻量级事务(Light-weighted Transaction)
前文可以看到,总的来说越严格的隔离级别意味着越低的性能,如果还要考虑数据分区(partition),这个现象会更加明显。因此更为年轻的 "NoSQL" 数据库几乎都不支持传统的事务。相反,它们声称自己支持“轻量级”事务,以 Cassandra 为例:1
2
3
4-- insert
insert into user (id, name) values ('123', 'foo') if not exists;
-- update
update user set name = 'bar' where id = '123' if name = 'foo';
上面是两条 CQL 语句展示了两个轻量级事务(注意 if 从句),可以看到这跟之前我们用 where 从句实现的乐观锁没什么不同。说白了就是提供了一个 CAS 原语,因此我更倾向于认为所谓的“轻量级事务”只是一个市场营销用语。
注:轻量级事务(Light-weighted Transaction)又被称为单行事务(Single-Object Transaction),与其对应的传统事务又被称为多行事务(Multi-Object Transaction)
在没有多行事务支持的情况下,业界出现了大量的 workaround 方案,其中比较出名的有 BASE,TCC,Compensate Transaction,我不否认它们的价值,但个人认为,这些方法的本质都是在业务上做出妥协,不同的业务需求可能有不同的妥协方式,它们最多只能被视为完成交易的方案,跟数据库领域的事务并没有什么关系,偏偏某些发布这些方案的人还试图用其特定业务场景的正确性来证明自己实现了”分布式事务“(要知道即便是 2PC 也只是一个原子提交协议,仅仅实现了事务的 "Abortability" 属性而已)。
好在随着技术的发展,近几年新兴的一些数据库产品(Google Spanner, TiDB)据说确实能够实现真正意义的分布式事务,尽管我非常好奇它们是如何做到的,无奈最近已经开始工作了,短期内应该是没有时间去研究了。