(封面图片来自 Consistency Models)
最近打算尝试一下翻译。由于我的英语基本停留在高中水平,所以不会严格按照原文来翻译,再加上我喜欢加入自己的理解(个人水平有限,所以我的理解应该也没啥参考价值)。所以有一定英语基础的同学还是建议自己阅读原文:Strong Consistency Models。
基础概念解释
一些专业术语翻译成中文后往往更加难以理解,因此我不会翻译这些词,下面先简单解释一些本文中用得比较多的术语,其中的定义来自于 Consistency Models 这篇文章。这里只是做一个笼统的翻译。
- Systems
分布式系统是一种并发 system,很多关于并发控制的研究可以直接应用到分布式 system 中。不过,大部分我们将要讨论的概念最开始是为单点并发系统设计的。它们之间在可用性和性能上还是有一些区别。
System 的逻辑状态会随着时间改变。比如说单个整型变量就可以是一个简单的 system,它有类似于 0, 3, 42 这样的状态。一个互斥锁 system 有两种状态:locked 和 unlocked. - Operations
一个 operation 是 system 从一种状态到另一种状态间的转移。比如说,一个单变量 system 可能有类似于读取和写入这样的 operation,它们分别用来获取和设置该变量的值。一个计数器可能有自增,自减,读取这样的 operation。 - Histories
一个 history 是一系列 operation 的集合,包括它们的并发结构。这里将其表述成一个包含 operation 的调用和完成的有序列表(an ordered list of invocation and completion operations)。 - Consistency Models
一个 consistency model 是一系列 history 的集合。我们用 consistency models 来定义哪些 histories 在 system 中是“好的”或者“合法的”。当我们说一个 history 违反了 serializability 或者不是 serializable 的时候,我们指的是这个 history 不在 serializable consistency model 允许的 history 集合。
正文
由于网络分区总是会发生,交换机,网卡(Network Interface Controller, aka NIC),主机硬件,操作系统,磁盘,抽象层,编程语言运行时,甚至程序语义自身,都在密谋着延迟,丢失,重复,或者乱排我们的消息,在一个不确定的世界,我们想要我们的软件维持直觉上的正确。但是什么是正确的事?我们怎样描述它?在这篇文章里,我们将会快速浏览一些“强”一致性模型,并且看看它们是如何在一起工作的。
正确性(Correctness)
有很多种方式来表达一个算法的抽象行为,这里,我们说一个 system 是由 state 和一些改变状态的操作 operation 组成的。当 system 运行时,它经历一系列的操作(history of operations)来从某种状态,转移到另一种状态。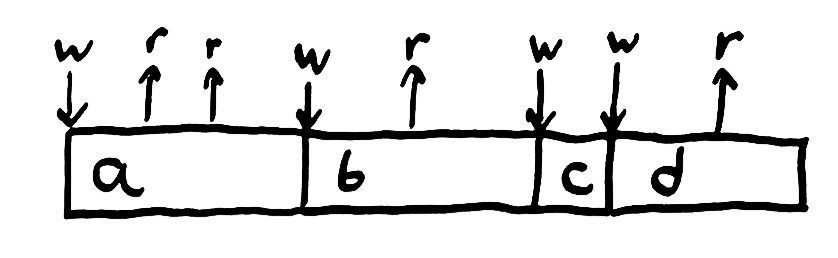
举例来说,我们的 state 可能是一个变量,operation 可能是写入或者读取该变量,在下面这个简单的 Ruby 程序中,我们多次写入和读取一个变量,并将其打印到控制台来演示读取操作。1
2
3
4x = "a"; puts x; puts x
x = "b"; puts x
x = "c"
x = "d"; puts x
对于程序的正确性,我们已经有一个直觉上的模型:它将打印 "aabd". 为什么呢?因为这些语句按顺序执行。首先我们写入值 a,然后读取值 a,然后写入值 b,如此往复。
一旦我们将一个变量赋值为某个值,比如 a,读取该变量就应该返回 a,直到我们再次改变这个值。读取一个变量返回该变量最新写入的值。我们称这种 system (单个变量与单个值)为 register。
从我们第一天开始写程序起,这种模型就已经刻在我们脑海中了,就像自然本能一样。如果一个变量在读取的时候返回的是任意值: a, b, moon. 我们就会说这个 system 是不正确的,因为这些 history 跟我们设想的模型不一样。
这暗示着关于 system 正确的一个定义:给定一些关于 operations 和 state 的规则, system 中的任意 history of operations 应该一直遵守这些规则。我们称这些规则为一致性模型。
我们用文字来描述对 registers 的规则,但是这些规则也可能是任意复杂的数学结构。“一次读取返回该读取前倒数第二次写入的值,加上3,如果该值是4,这次读取就允许返回 cat 或者 dog”是一种一致性模型。“每次读取都返回0”也是一致性模型,甚至于“没有任何规则,所有的 history 都是允许的”也算,这算是最容易满足的一致性模型了,所有的 system 都遵守这个模型。
更严谨的来看,我们说一致性模型是所有允许的 histories 的集合。如果我们运行一个程序,我们会得到一个 history of operations,如果该 history 在允许的集合内,则这次运行是满足一致性要求的。如果一个程序时不时得到一个不在指定集合的 history,我们说这个 system 是不符合一致性要求的。如果所有可能得到的 history 最终都包含在该集合内,则这个 system 满足该模型。我们想要的是现实中的 system 满足“直觉上正确”的一致性模型,这样我们才能写出行为可预测的程序。
Concurrent histories
译注:注意下文的 process 跟我们平时理解的进程不一样,这里指的是一个逻辑上的单线程程序,一个 process 一次只做一件事。它的实现可能涉及到多线程,多进程,甚至多个物理节点,但只要这些组件最终能表现得像一个逻辑上的单线程程序就可以了。
现在来设想一个并发程序,比如说一个 Node.js 或者 Erlang 程序。有多个逻辑线程,这里我们用术语 "processes" 来表述。如果我们执行一个有两个 processes 的并发程序,它们共同操作同一个 register。这可能会违反我们早先的不变性。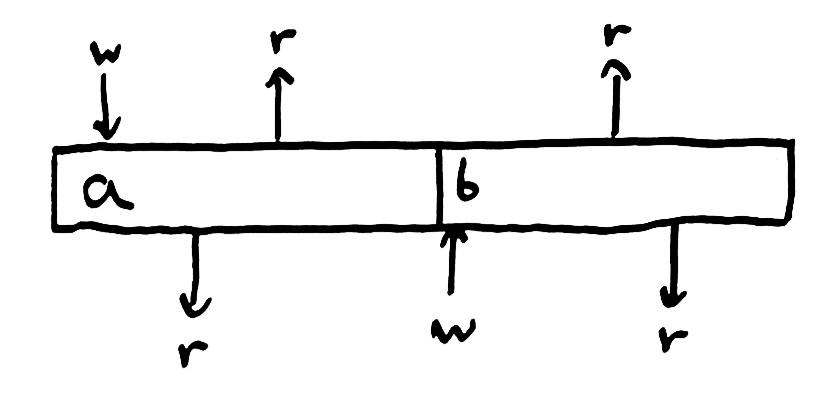
这里我们分别称两个工作的 processes 为 "top" 和 "bottom"。top process 尝试 write a,然后执行两次 read 操作。与此同时,bottom process 尝试 read,write b,再 read。因为程序是并发的,这两个 processes 的操作可能以多种方式排序。只要这些排序方式分别满足单个 process 指定的操作序列就可以了。
即使我们保证了对于单个 process 而言,operations 会按其指定的顺序执行,但我们先前对 register 的不变性定义依然被破坏了。top process 写入 a, 读到 a 值,接着又读到了 b ,这并不是它写入的值。因此,为了更好的定义并发,我们必须对我们直觉上的一致性模型做出修改。现在,一个 process 允许读取到任意 process 最近写入的值。该 register 变成了两个 process 协作的地方,它们共享 state。
锥形光束(Light cones)
译注:这里的光束(light)是一个假想模型,用来模拟消息随着时间推移从 process 抵达 register 并最终返回所经过的路径。
现实还不止于此,在几乎所有真实的 system 中,processes 之间是存在距离的。比如说,内存中一个未缓存的值,在 DIMM(Dual Inline Memory Module) 中可能距离 CPU 30厘米远。我们的 light 需要花费整整一纳秒的时间来走过这段距离(真实的内存访问会更加慢)。一个值可能存在于几千米外的某个数据中心的某台机器上,一条消息在“路上”可能需要花费几百毫秒的时间,目前来说,我们从物理上改变不了这个事实。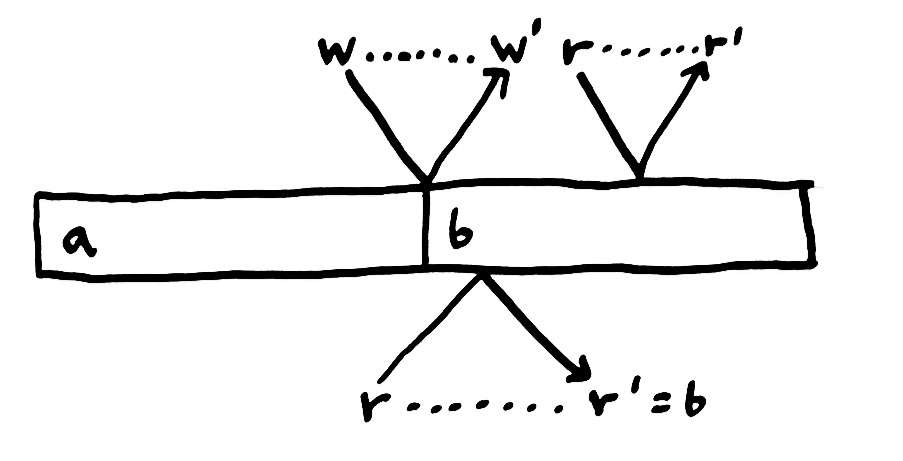
这意味着我们的 operation 不再是立即发生的,有些时候它们快到我们可以忽略不计,但是总的来说,operations 需要在路上花费一些时间。大致的情形是:我们执行一个写指令,该指令到达内存,或另一台计算机,或者月球;内存修改状态;发回一条确认消息,告诉我们这个 operation 的确执行成功了。
消息从一个地方到另一个地方之间的延误,预示着同样的 history of operations 可能会导致不同的执行结果。消息到达的快慢可能导致它们实际的执行顺序跟我们期望的不一样。这里,bottom process 在值是 a 的时候调用读操作,当该消息还未到达目的地的时候,top process 调用写入 b,恰巧这个写入操作比读取操作先到达。最后 bottom process 在值为 a 的时候读取,最终却读到了 b。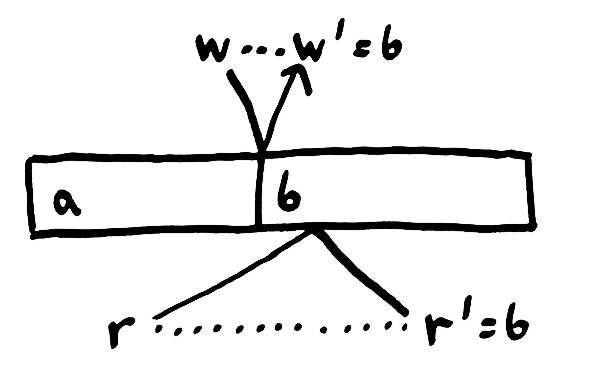
这个 history 再次违背了我们现有的 concurrent register consistency model。bottom process 在调用读操作的时候并没有读取到当前值。也许你会说我们可以用操作的完成时间(completion time),而不是调用时间(invocation time)来作为 operation 的真实时间。同样的道理,该结果依然不正确,因为如果读操作比写操作先到达,bottom process 会收到 a 值,但实际的值确是 b。
在分布式系统中(一个 operation 需要时间来到达生效点),我们需要再次放宽我们的一致性模型,来允许这些带有歧义的顺序发生。
线性一致性(Linearizability,又称 atomic consistency)
仔细思考一下,上文的事件发生顺序还是有界的。一条消息到达数据源的时间不可能早于消息的发出时间,所以一个 operation 不可能在其调用之前就生效。同理,收到执行成功的确认消息的时间也必定晚于 operation 生效的时间,也就是说 operation 不可能在完成时间之后才生效。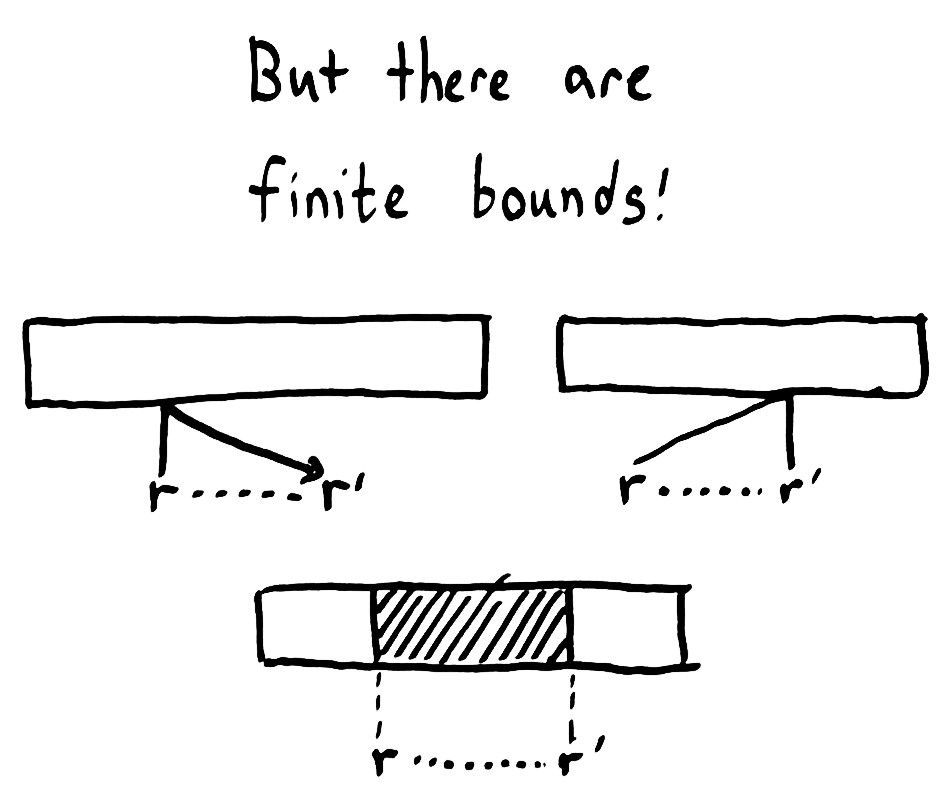
如果我们假设所有的 processes 都与一个全局的状态对话,并且所有 operation 对该状态中心的影响是原子级的,对彼此之间没有依赖。在这些规则下我们可以排除掉很多可能的 histories。我们知道每个 operation 都会在它的调用时间与返回时间之间的某个时间点生效。
我们称这种一致性模型为线性一致性,因为尽管 operations 是并发的,而且需要时间来完成,但是它们总是有可能能保持一个合理的线性顺序的。
线性一致性是一种非常强壮的模型,一旦一个 operation 完成,所有人都能看到它的结果(或者一些更新的结果),因为所有的 operation 都会在它完成前生效,并且后续调用的 operation 肯定会在调用的时间点后生效。这就意味着一旦我们成功的写入了 b,所有后续的读取操作都会看到 b(或者如果发生了其它的写入,我们会看到比 b 更新的值)。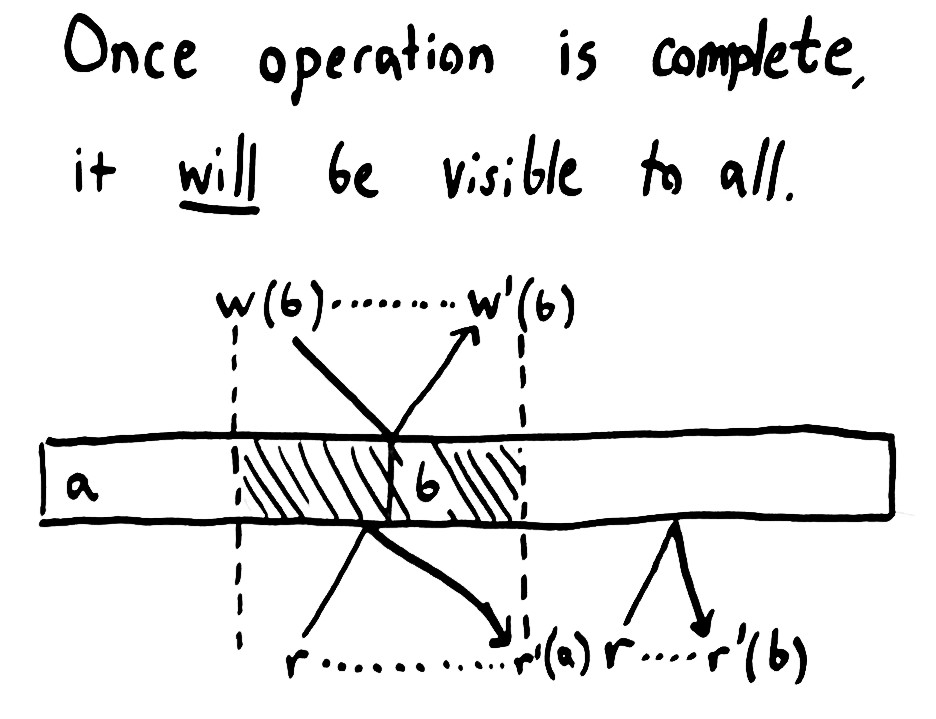
我们可以利用线性一致性的原子级别约束来安全的修改(mutate) state。我们可以定义一些类似于 compare-and-set 的 operation,即当且仅当当前 register 处于某个值的时候,将其设置为新的某个值。我们可以用 compare-and-set 作为实现 mutexes, semaphores, channels, counters, lists, sets maps, trees 的基础,所有的共享数据结构都变得可行了,线性一致性能够保证我们安全的更新这些数据。
不止于此,线性一致性保证了在一个 operation 完成后,其修改结果对其它的参与者可见。因此它可以防止 stale reads,即保证每个 operation 都能读取到处于调用时间与完成时间之间的某个值,而不是调用前的值。同时它也可以防止 non-monotonic reads,即保证后续的读取操作只可能读取到更新的值。
因为这些约束,满足线性一致性的 systems 非常容易理解以及预测,这也是为什么它被选择作为很多并发编程结构的基础。在 Javascript 中所有的变量都是满足线性一致性的,同样还有 Java 中的 volatile 变量,Clojure 中的 atoms,Erlang 中的独立 processes。大多数语言都有 mutexes 和 semophores 实现,这些也是 linearizable 的。
但是如果我们不能满足这些约束会发生什么呢?
顺序一致性(Sequential consistency)
如果我们允许 processes 倾斜时间,比如说允许 operations 在调用前就生效,或者在完成后才生效,但是对任意 process,来自该 process 的 operations 必须按其指定的顺序生效。这样我们就得到了一个相比之下稍弱的一致性模型,即 sequential consistency.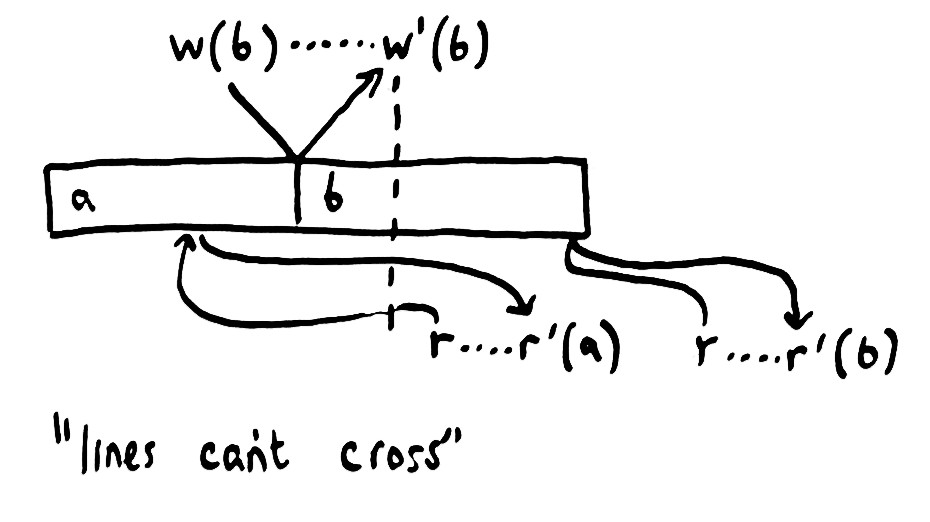
Sequential consistency 相比线性一致性允许更多的 histories。但是它仍然是一个有用的模型:我们每天都在使用它。比如说当一个用户上传一部视频到 youtube 的时候,youtube 将该视频存入一个队列,等待后续的处理,然后直接返回一个网页。我们在当时无法直接看到该视频,视频上传行为需要等视频处理完后才算生效。这里的队列移除了同步行为,但保留了正确的顺序。
很多缓存实现也像 sequentially consistent systems。如果我在 Twitter 上发一条 tweet。它需要花一些时间来渗透各种缓存层。不同的用户看到这条消息的时间可能不一样,但是每个用户始终会按照顺序看到我们的 operations。一旦看到了,它不会再消失,如果我发了多条评论,它们也会按顺序变得可见。
译注: 注意上文中的“倾斜时间”,“调用前生效”,“完成后生效”可能从字面上很难理解,这里补充一个例子。比如在 Java 程序中一个可以被多个线程访问的变量(注意没有
volatile关键字,也没有加锁),其中有一条语句是修改这个变量,这条语句执行完意味着已经过了 completion time,但是实际上有可能该 operation 并没有真的“生效”。因为其它线程可能并不能看到该修改结果。
因果一致性(Causal consistency)
我们有可能并不需要保持一个 process 所有的 operation 都有序,有时只要因果相关的 operation 有序就行了。如果我们对每个 operation 都存入一条类似于“我依赖于 operation X”这样的信息,数据源就可以延迟 operation ,直到它依赖的所有 operation 都生效为止。
这种模型比 Sequential consistency 要弱,在这种模型中,即便对于同一个 process 来说,不相关的 operation 也可能以任意顺序执行。但由于互相依赖的 operation 依然有序执行,因此依然阻止了很多违反直觉的行为。
Serializable consistency
如果我们说任意 history of operations 一定等价于某种原子排序(If we say that the history of operations is equivalent to one that took place in some single atomic order),但对 operation 的调用与完成时间不作出任何承诺。我们就获得了一种被称为 serializability 的一致性模型。这种模型跟你的预期相比,既强壮得多,也弱小得多。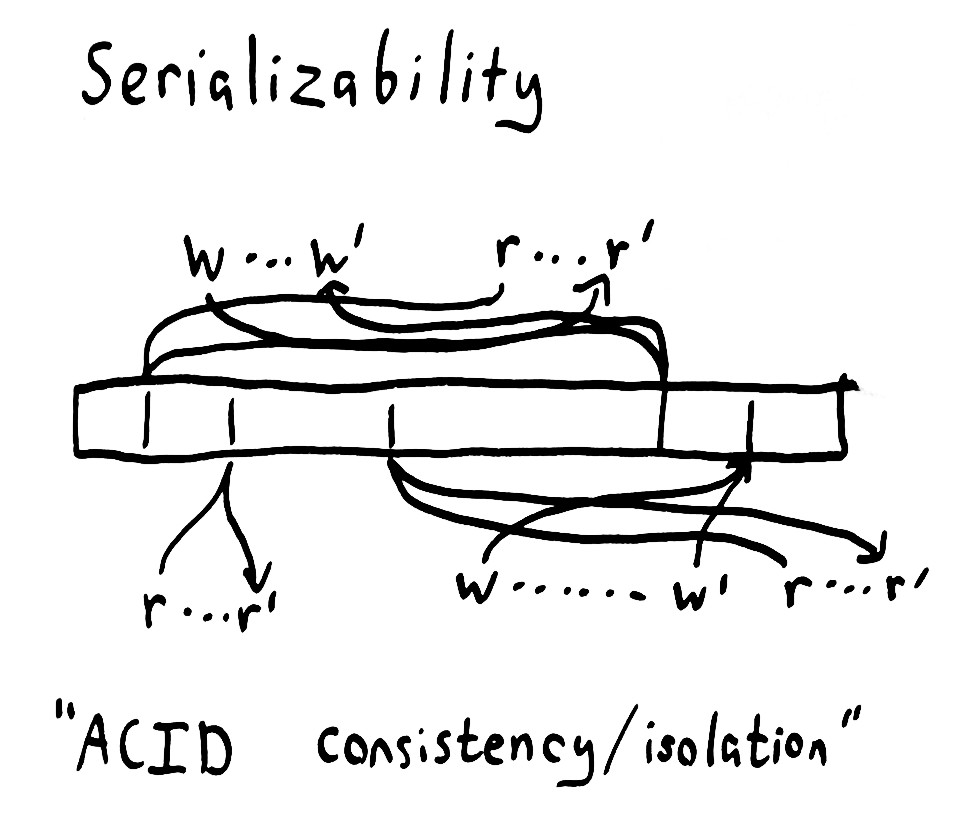
Serializability 可以非常的弱,因为它对时间与排序都不设限制,在上面的图中,它表现得就像一个消息可以传回任意远的过去或未来,因果关系也允许被破坏。在一个 serializable 的数据库中,一个类似于 read x 这样的事务允许在 time 为 0 的时刻执行,也可能那时 x 还没有被初始化,或者它也可能被延迟到无穷远的未来!事务 write 2 to x 可能现在就执行,也可能被延迟到永远也不会执行。
比如说在 serializable system 中,下面这个程序1
2
3x = 1
x = x + 1
puts x
打印 nil, 1, 或者 2 都是允许的,因为 operations 可能以任意排序生效,这是一种非常弱的约束,我们假设每行代码代表一个 operation ,并且所有 operation 都成功执行了。
另一方面,serializability 模型又非常强。下面的程序1
2
3
4print x if x = 3
x = 1 if x = nil
x = 2 if x = 1
x = 3 if x = 2
只有一种排序方式,虽然它不会按我们写的顺序执行,但是它能够可靠的将 x 按顺序修改成 nil, 1, 2, 3。并且最终打印3。
因为 serializability 允许将 operations 任意排序,因此在真实的应用中这种模型并没有什么用,很多数据库声称提供 serializability 模型,但实际提供的是 strong serializability 模型。这种模型有着跟 linearizability 一样的时间界限。更糟糕的是,很多 SQL 数据库中所谓的 SERIALIZABLE consistency level 实际上用的是某种更弱的模型,比如说 repeatable read, cursor stablity, 或者 snapshot isolation。
一致性的代价
我们说过“弱”的一致性模型相比“强”一致性模型允许更多的 histories。比方说 Linearizability 模型,向我们保证了 operations 会在调用时间与完成时间之间的某个时间点生效。但是维护这样的秩序是需要协作的。大致来说,我们排除的 histories 越多,系统的参与者所需要的沟通就越多,并且需要更加谨慎。
你也许已经听过了 CAP 理论,它说的是任意 system 最多只能保证实现 consistency, availability 和 partition tolerance 的其中两个。更精确的定义是:
- Consistency 意味着 Linearizability。
- Availability 意味着对任意一个在线节点的请求必须在有限时间内成功的完成。因为我们允许网络分区持续无限久,这意味这我们不能简单的将回复推迟到网络分区结束。
- Partition tolerance 意味着允许网络分区发生。当网络可靠时,保持 consistency 和 availability 是很容易的。当网络不可靠时,同时保证这两者已经被证明了是不可能的。如果你的网络不是完美可靠的(它本来就不可能是),你就不能选择 CA,这意味着所有实践中的分布式系统最多只能保证 AP 或者 CP。
“等等!”,也许你会说。“Linearizability 并不是唯一的一致性模型,为了绕过 CAP 定理,我还可以提供 sequential,或者 serailizability,或者 snapshot isolation 一致性!”
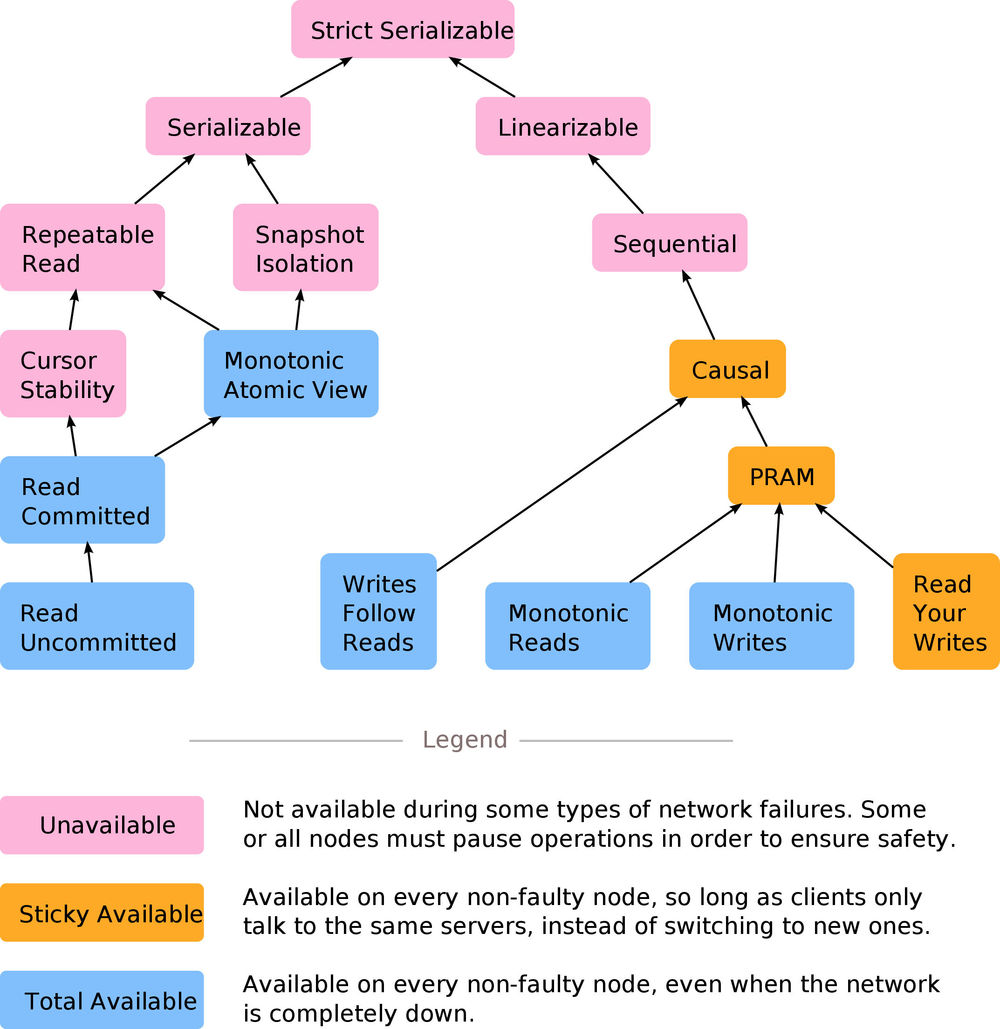
没错,CAP 定理只说了我们无法构建百分百可用的 linearizable systems。问题在于还有其它的证明告诉了我们你也无法构建百分百可用的 sequential, serializable, repeatable read, snapshot isolation 或者 cursor stability 或者任意比这些模型 "strong" 的一致性模型。在下图中(该图等价于封面图,所展示的理论来自于Highly Available Transactions paper),红色的模型都是无法完全可用的。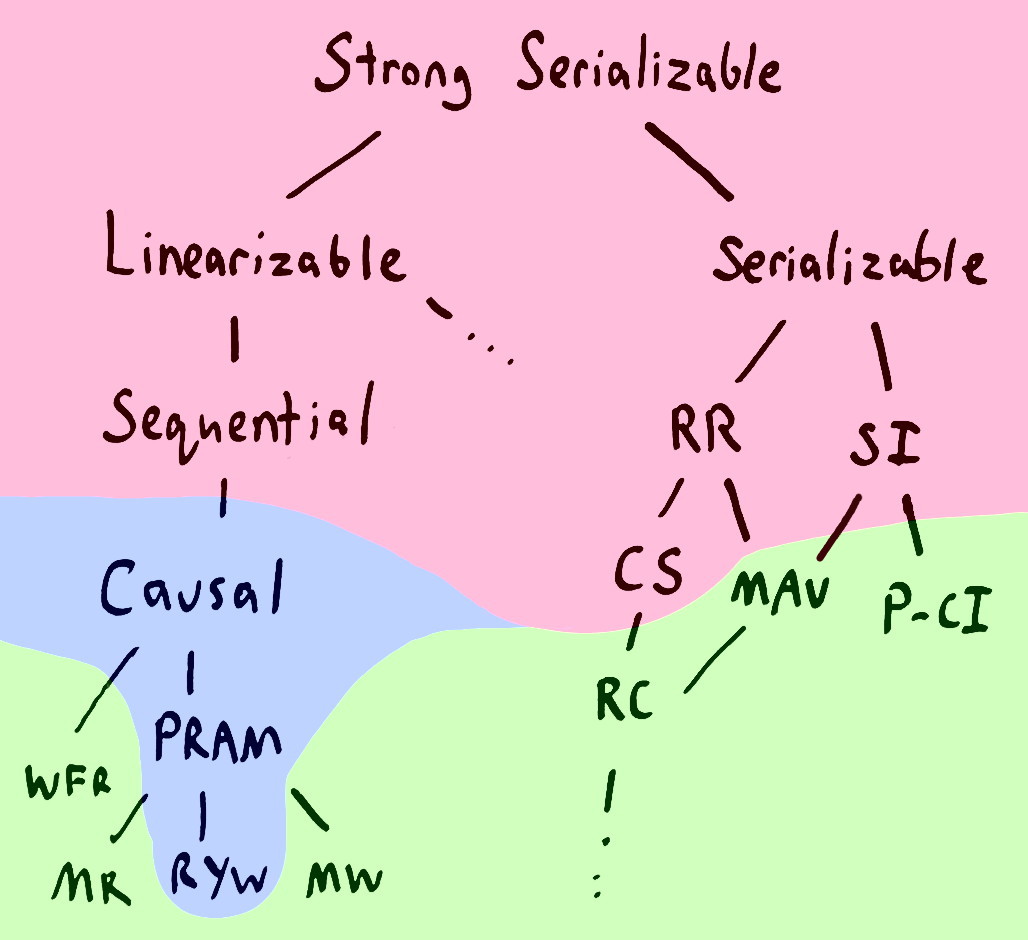
如果我们稍微放松一些对 availability 的要求,比如说客户端永远只会与相同的服务端节点会话,这样的话其中一些模型是可以实现的,比如说 causal consistency, PRAM(Pipelined RAM, also FIFO consistency), 和 read-your-writes 一致性。
如果我们要求百分百可用,我们可能实现的是 monotonic reads, monotonic writes, read committed, monotonic atomic view 等等。一些分布式数据库提供了这些模型,比如说 Riak 和 Cassandra,或者被设置成低隔离级别的 ANSI SQL 数据库。这些模型不像我们之前在图中画的那样线性有序,它们只提供部分有序 (partial oerder)。
一种混合方式
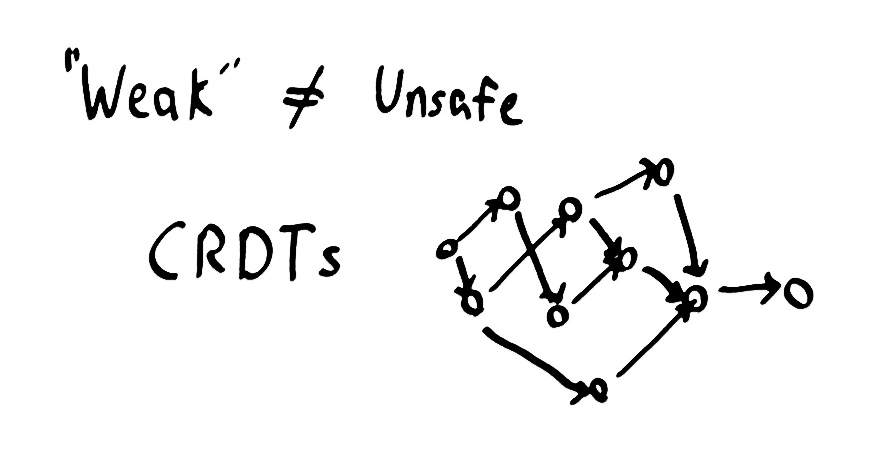
一些算法需要 linearizability 来保证其正确性。比如说,如果我们想构建一个分布式锁服务,没有时间界限,我们可能会持有一把来自过去或者未来的锁。另一方面,也有很多算法不需要 linearizability。比如说,一些可以被表示成 CRDTs(Convergent and Commutative
Replicated Data Types) 的最终一致性集合只需要"弱"的一致性模型就可以实现。
更强壮的一致性模型往往倾向于需要更多的协作,即跟多的消息交换,来保证它们的 operations 出现在正确的顺序。它们不仅可用性更低,而且可能导致更高的延迟,这也是为什么默认情况下,现代的 CPU 内存模型不是 linearizable 的。除非你显式的指明,不然的话现代的 CPU 可能会打乱相对其它核心的内存 operations 的顺序,或者更糟。这么做对整体性能的提升是现象级的。一些在地理上不同节点相距甚远的分布式系统,相互间的沟通可能会有上百毫秒的延迟,这样的系统也会经常做类似的妥协。
因此,在实际场景中,我们经常使用混合多种一致性模型的数据存储方案来完成我们对 redundancy, availability, performance, 和 safety objectives 的需求。为了可用性和性能考虑,只要条件允许,我们优先选择“弱”一致性模型。在必要时才选择“强”一致性模型。比如说你可以将大容量的数据写入 S3, Riak 或者 Cassandra,然后将它们的引用线性化的写入 Postgres, Zookeeper 或者 Etcd。一些数据库实现了多种一致性模型,比如关系型数据库中的隔离级别是可调的,或者 Cassandra 和 Riak 提供 linearizable 事务。最后:任何声称他们的一致性模型是唯一正确选择的人,很有可能只是在做产品推销。强一致性,可用性和性能之间,始终存在一种“鱼和熊掌不可兼得”的关系。
补充说明
下面的链接是一些翻译过程中阅读过的文章或资料: