
上篇聊到了插入排序与希尔排序,它们分别擅长处理小型和中型输入,今天来聊两个适用于大型数组的排序算法,与上篇类似的是,这篇的两个算法设计思路也非常相似,它们都基于分治思想。
一.分治(Divide and Conquer)
分治指的是将大问题拆分成相同类型的小问题,再联合小问题的解,从而最终解决大问题的一种算法设计思想。传统上认为分治算法必须将问题拆分成两个或多个子问题。因此二分查找不算分治算法。因为它只有单一子问题。下面先来一段“经典”代码:1
2
3
4public static int fib(int N){
if(N<=1) return 1;
return fib(N-1)+fib(N-2);
}
上面这段代码依据给定N,计算斐波那契数列,之所以说它经典是因为这段代码作为反面教材出现在各大编程入门书籍中。它在字面上完全符合上面对分治的定义,但却效率低得惊人。作为子问题,fib(N-2)被重复计算了两次(fib(N-1)中也要计算fib(N-2))。因此它并没有将子问题完全“分开”。本文要讨论的两种排序算法跟上面的代码结构非常类似,但你必须要能够理解其中本质的不同。
二.最快的排序算法
上一篇提到基于比较的最快的排序算法不可能优于O(NlogN),你可能会好奇它是怎么来的,大牛们采用香农信息论(information theory)证明,wiki上关于信息论的描述看完以后我反正是一个大写的懵B,这里提供一个更接地气的证明方法。假设有一个含有N个不重复元素的数组,那么它共有N!(阶乘)种不同状态,因为N个不同元素有N!种排列,每进行一次比较,比较结果有两种可能(大于或小于),这将排除一些可能的状态,可以构造一棵二叉决策树来表示这个过程,下图表示对A,B,C三个元素排序的过程:
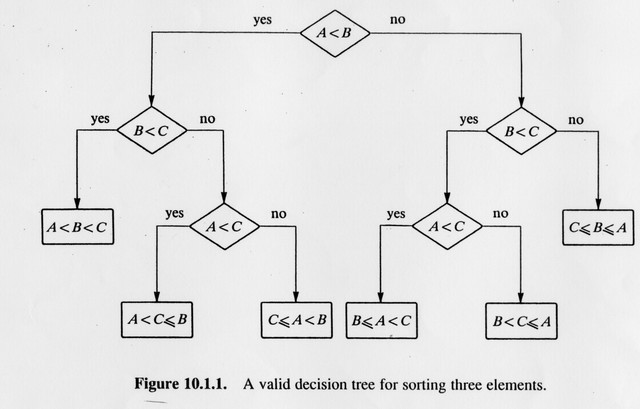
这颗树的树叶表示所有可能的排序方式,而它的高度则是在最坏情况下需要的比较次数。不难推测出,对于给定的含有N个元素的数组,决策树必须要能够容纳下N!个叶节点,才能应付所有可能的情况,否则一定能构造一些输入,导致排序失败。了解了这一点,下面问题就简单多了,我们需要一棵多高的树才能保证其能够容纳N!个叶节点?
了解二叉树基本性质的人可以不假思索的回答,一棵高度为h的二叉树最多可以含有$2^h$个叶节点(此时人们称其为完全二叉树),要让我们的排序算法万无一失,就必须保证 $2^h\geq N!$,即 $h(\text{比较次数})\geq log(N!)$。
到这里我们已经可以得出结论,任何基于元素间比较的排序算法复杂度不可能优于O(logN!),可我还有一个问题,logN!到底是多大?阶乘计算总是过于复杂,人们一般采用斯特灵公式来求取一个近似值,遗憾的是我的数学能力仅停留在高中水平(高中数学还很少及格),因此wiki上关于这段公式的内容在我眼里大概是这样的“~!@#$%^&*#@^_^!”,好在stackoverflow上有一个更加简单的解法,Let's see:
$$\text{首先依据对数的性质可以得到:}log(N!)=log(N)+log(N-1)+log(N-2)+\ldots+log(N/2)+\ldots+log(1)$$$$\text{直接丢弃求和等式的右半部分可得:}\Rightarrow log(N!)\geq log(N)+log(N-1)+log(N-2)+\ldots+log(N/2)$$$$\Rightarrow log(N!)\geq log(N/2)+log(N/2)+log(N/2)+\ldots+log(N/2)$$$$\Rightarrow log(N!)\geq (N/2)log(N/2)=(N/2)logN-N/2$$$$\Rightarrow log(N!)= \Omega(NlogN)$$这里的$\Omega$指的是函数渐进增长的下界,可以依据类似的方式得到其上界:$$log(N!)=log(N)+log(N-1)+log(N-2)+\ldots+log(N/2)+\ldots+log(1)$$$$\Rightarrow log(N!)\leq log(N)+log(N)+log(N)+\ldots+log(N)=N\times log(N)$$$$\Rightarrow log(N!)=O(NlogN)$$
当既有$f(N)=O(g(N))$(upperbound)又有$f(N)=\Omega(g(N))$(lowerbound)时,我们说$f(N)=\Theta(g(N))$(tightbound)。在此例中即$log(N!)=\Theta(NlogN)$,如果你觉得这些关系很混乱,只要知道$\Theta$是O的充分不必要条件即可。
结论:任何基于比较的排序算法,其最坏情形复杂度不可能优于$\Theta(NlogN)$
三.归并(Merge)排序
你可能以前从没听过归并排序,但你不可能没听过它的作者。现代计算机之父约翰·冯·诺伊曼于1945年发明归并排序,这被认为是最早在计算机上正确应用分治思想的算法。上码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static void mergeSort(int[] arr){
int[] aux=new int[arr.length];
mergeSort(arr,aux,0,arr.length - 1);
}
private static void mergeSort(int[] arr,int[] aux,int lo,int hi){
if(lo>=hi) return;
int mid=(lo+hi)>>1;
//divide
mergeSort(arr,aux,lo,mid);
mergeSort(arr,aux,mid+1,hi);
//merge
System.ArrayCopy(arr,lo,aux,lo,hi - lo + 1);
int i=lo,j=mid+1;
for(int k=lo;k<=hi;k++){
if(i>mid) arr[k]=aux[j++];
else if(j>hi) arr[k]=aux[i++];
else if(aux[i]<aux[j]) arr[k]=aux[i++];
else arr[k]=aux[j++];
}
return;
}
归并排序的思路是先找到输入数组的中间元素(mid),然后根据中间元素将输入数组划分成两部分,整个过程递归进行,分到最后每个子数组将只有一个元素,此时所有的子数组就已经有序了(只有一个元素的数组是有序的),然后对所有子数组执行归并(merge)操作,此时唯一需要做的就是保证归并完成后数组仍是有序的,如图:
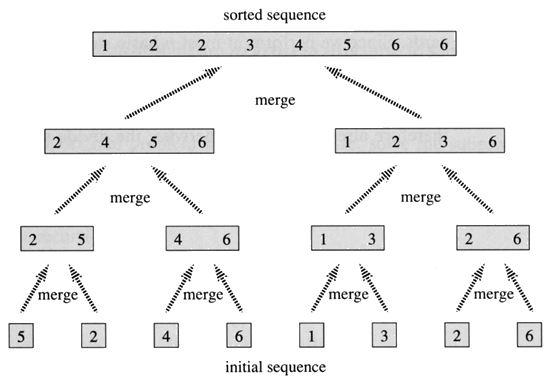
分治算法大多满足于同一个运行时间方程,即T(N)=2T(N/2)+O(N),其中2T(N/2)代表求解两个同等规模的子问题需要的时间,O(N)是联合子问题的解需要的时间,对归并排序而言则指的是merge需要的时间,这里可以简单的将merge所需要的时间用N(实际是cN,这不影响结果)来代替。求解该方程是相当简单又不失趣味的过程:
$$T(N)=2T(N/2)+N \Rightarrow T(N)/N=T(N/2)/(N/2)+1$$$$T(N/2)=2T(N/4)+N/2 \Rightarrow T(N/2)/(N/2)=T(N/4)/(N/4)+1$$$$\vdots$$$$T(2)=2T(1)+1 \Rightarrow T(2)/2=T(1)+1$$将式子一层层代入后可得$T(N)/N=T(1)+logN\text{(等式右边一共有logN个1相加)}$,已知$T(1)=1$,最后等号两边同时乘以N得到:$$T(N)=N+N \times logN=O(NlogN)$$
以上证明过程假设了N是2的幂,即每次都能将输入数组分成两个正好同样大小的子数组,当输入数组是奇数的时候求解过程要麻烦一些,但结果是一样的。另外还可以采用类似的方法证明归并排序所需的比较次数最低为(NlogN)/2,最高为NlogN(注意这里没有O),结合上一节的理论,可以总结一个非常拗口的结论,即不可能找到任何基于比较的排序算法,在最坏情况下所需比较次数少于归并排序在最坏情况下的比较次数。如果一条定理读起来非常拗口,往往意味着它没什么卵用,这里也是如此。
归并排序最令人诟病的缺陷在于它需要线性的空间复杂度,并且将元素从数组复制到辅助数组这个过程浪费了大量的时间。再加上考虑算法是否高效不能仅考虑最坏情形(还记得上篇文章插入排序与选择排序的例子吧?),就平均速度而言它在高级排序算法中没有优势,种种因素导致归并排序使用场景非常有限,而这里我把它列为主流排序算法有三个原因:
- 它是基于比较的排序算法中,所需比较次数最少的。
- 当空间不是问题的时候,人们有时出于稳定性(参考上篇文章“排序算法的稳定性”)考虑而选择归并排序,比如说JDK对引用类型使用归并排序。
- 它与快速排序设计思路类似,很适合放在快速排序之前讨论,就像上篇插入排序与希尔排序的关系一样。
结论:如果稳定性很重要而空间又不是问题,有时可以选择归并排序。
四.快速(Quick)排序
快速排序是目前使用最广泛的排序算法,它的作者是图灵奖得主C.A.R.Hoare,正如该算法的名字一样,它是实践中最快的已知排序算法,它在平均情况下的时间复杂度是O(NlogN),这样看起来并没有什么特别之处,它之所以性能突出是因为其高度优化的内循环,换句话说,假定它的时间复杂度为k*NlogN+b,那么这里的k比其它线性对数级的算法要小。最原始的快速排序在最坏情形时复杂度为O(N^2),但这完全可以通过一些编程技巧来避免。下面看代码:
1 | public static void quickSort(int[] arr){ |
上面这段代码是否与归并排序如出一辙?因为它们都建立在分治思想之上,归并排序选取中点(mid)将数组均分成两个子数组,仔细思考一下,排序的merge过程建立在两个子数组已经有序的前提之下,那假设此时左子数组最大的元素小于右子数组最小的元素,是否可以完全去掉merge过程?举例来说假设一个数组的左子数组是[1,3],右子数组是[5,6],那么merge过程完全是多余的,因为该数组已经有序了。理解了这一点,你便理解了快速排序。剩下的问题是,如何找一个点切分数组,使其左子数组都小于等于该点,右子数组大于等于该点。
上面提到的这个点,我们一般称其为pivot(枢纽元),而选取这个点的过程一般称其为partition(分区),你可以完全不必理会这些专有名词,它们的主要作用在于吓唬那些不懂原理的人,让这些人对快速排序望而却步。但既然我们已经明白其原理了,这里我还是会使用它们来保持文章与主流书籍的一致性。下面先来看一种简单的分区思路:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
*直接选取第一个元素lo作为pivot,使用两个指针(i,j)扫描数组,i,j朝数组中间移动
*遇到arr[i]>=pivot则i停止,遇到arr[j]<=pivot则j停止,交换i,j对应的元素,重复该过程直到i,j相遇
*当整个过程停下来时将pivot与a[j]交换位置,从而完成分区
*
* left part center part right part
* +--------------------------------------------------------------+
* lo | <= pivot | | >= pivot |
* +--------------------------------------------------------------+
* ^ ^ ^
* | | |
* pivot i-> <-j
*
*/
private static int partition(int[] arr,int lo,int hi){
int i=lo+1,j=hi;
while(true){
while(arr[++i]<arr[lo] && i < hi);
while(arr[--j]>arr[lo]); //这里不需要判断j>lo,因为当j=lo时,arr[j]>arr[lo]不可能成立
if(i>=j) break; //i,j相遇时停止
exchange(arr,i,j);
}
exchange(arr,lo,j);
return j;
}
眼尖的同学一眼就能看出该程序的问题,考虑数组所有元素都等于pivot的情况,当i遇到等于pivot的元素时停下,j遇到等于pivot的元素也停下,然后i与j发生一次交换,这实际上什么也没干。了解这里为什么要多此一举,需要先分析算法的复杂度。
不难想象,快速排序的最好情况是每次选取的pivot正好在数组的中间,从而每次都把问题划分成相等规模的子问题,此时该算法的时间复杂度为T(N)=2T(N/2)+cN,cN表示分区过程消耗的时间,求解该方程的过程与刚才计算归并排序复杂度的过程一模一样,如果你记性还算不错的话应该知道结果是O(NlogN)。下面简单分析一下它的最坏情况,即每次选取的pivot都正好是数组最小的元素,此时划分的左子数组只有0个元素,右子数组为N-1个元素(去掉pivot)。其复杂度有如下关系:
$$T(N)=T(0)+T(N-1)+cN$$$$T(N-1)=T(0)+T(N-2)+c(N-1)$$$$T(N-2)=T(0)+T(N-3)+c(N-2)$$$$\vdots$$$$T(2)=T(0)+T(1)+c(2)$$
同样一顿代入后,可以得到$T(N)=(N-1)\times T(0)+T(1)+c(N\times(N-2)/2)$,其中c(N(N-2)/2)是由等差数列的求和公式而来。已知T(0)=T(1)=c,最后得到:
$$T(N)=c(N-1)+c+c(N(N-2)/2)=O(N^2)$$
在这种情况下,每次递归所做的仅仅是将pivot元素放到了正确位置了,这就跟选择排序一样低效。所以有人干脆选择在排序之前将数组随机打乱以降低发生这种事的可能性,Sedgewick在其书上写到,对于一个较大的数组,先将其随机打乱再进行快速排序,其时间复杂度是平方级的概率比你的电脑在排序时被闪电击中的概率要小得多。为此我还特意在网上查了一下电脑被闪电击中的概率,然而却没有得到满意的答案,因此我不太喜欢这种方式。后面你还会看到,大牛们发明了很多经过实践验证的优化手段,足以避免我们的电脑在排序的时候被闪电击中。
计算最佳与最坏情况的复杂度总是比较简单,而快速排序的平均复杂度又是如何得到的?我一直在盘算能不能通过一些写作技巧把这个问题糊弄过去,因为我查了很多资料,发现证明其平均复杂度的方式要么涉及概率学,要么涉及微积分,要么两个都涉及。前面我大概已经交代过我的数学水平了,总之,快速排序的平均复杂度是O(NlogN),如果话说到这个份上你还要问我为什么,我想我们是没办法做朋友了。
咳,咳!还记得最开始的问题码?如果数组所有元素都等于pivot,i与j会不断发生无意义的交换,但最终j会停在数组的中间,而假设i与j遇到等于pivot的元素时都不停下,则j最终会停在数组的最左边,此时你将得到一个$O(N^2)$的排序算法。
结论
快速排序是已知最快的排序算法,大多数场景都可以优先选择快速排序。而它的缺点是不稳定(注意这里的稳定指的不是“效率不稳定”,参见“排序算法的稳定性”),运行效率在一定程度上依赖于概率(但通常比其它算法快),实现它的内循环(partition)需要一定的编程技巧(但这也给编程高手留下了足够的优化空间)。
下篇文章来聊聊快速排序的优化历程。
本文参考链接