
排序算法在很多计算机应用中都扮演着重要角色,同时也是大部分算法课程中不可或缺的一个章节。然而现如今的程序开发越来越模块化,程序员除了在技术面试的时候,几乎不存在任何应用场景需要手写一个排序算法,再则很多像我一样的学渣,看到“市面”上繁杂多样的排序算法就头疼,因此我打算在这里聊聊四种我个人认为比较主流的排序算法,看看当我们调用Arrays.sort()的时候到底发生了什么。
一.约定
为了更加方便的表达意图,下面是关于本文的一些约定
- 输入的规模
文中使用N代表输入的规模,比如说N=100,表示将100个元素排序 - 对数
除非有特别的说明,文中所有的对数都是以2为底的,即logN表示以2为底N的对数 - 代码
文中的代码(java或js)大多数只截取关键片段,无法直接运行,关于这些算法的完整代码网上到处都是,这不是本文的核心,我相信文章使用尽可能少的代码对阅读者更友好,在文中写代码只能代表我无法用简短的人类语言来描述这部分意图。
二.简单的概念
在正式开始前先简单介绍几个基本概念(有经验的程序员请一定跳过这个部分)
排序算法的稳定性
我刚开始学编程的时候看到“不稳定的算法”,首先想到的是“是不是这种算法有时无法将数组恢复有序?或者说有时运行非常快,有时永远也得不出结果?”事实上上面两种情况只能称作有bug的算法,算法的稳定性指的是当有两个元素有相同的主键的时候,算法是否能保证在排序前后这两个元素的相对位置不变,比如有一个数组1[{id:1,name:'foo'},{id:1,name:'bar'}]当依据id对这个数组排序后,是否还能保证foo在bar的前面。如果可以,则该排序算法是稳定的。
算法分析
我们应该怎样来判断一个算法,或者说一段代码的性能?最简单的方法通过反复测试来鉴别,但这显然太没效率了。我们需要在算法的设计阶段就能大致预测出算法能跑多块。因此高德纳(D.E. Knuth)首先提出构造数学模型来描述任意程序的运行时间,简单来说假设计算机执行每条语句的耗时是一个常数C,假设程序需要执行n条语句才能完成计算,则程序的总运行时间是C*n。常数C往往跟计算机硬件,使用的编程语言(PHP是世界上最好的语言!),CPU资源分配等相关,因此我们只需要关心n就可以了,而影响n的最关键因素是算法中的循环与递归。举个简单的例子:1234567int N=arr.length;for(int i=0;i < N;i++){for(int j=i+1;j < N;j++){if(arr[i]+arr[j]==0) return true;}}return false;上面这段代码搜索给定数组中是否包含两个和为零的元素,其中执行次数最多的是处于内循环中的判断语句,最坏的情况下要执行N*(N-1)次,当N足够大时,N*(N-1)≈N^2。于是我们可以说上面这段代码在最坏情况下运行时间大致为 C*(N^2),我们把这称为最坏情况下的时间复杂度。
同时,算法分析还应该考虑运行算法需要多少额外的存储空间,即空间复杂度,但由于空间复杂度往往很容易计算,因此不必在上面花太多时间。
顺带提一下,上面这段代码很常见,但不适用于大规模输入的情况,学过算法的同学应该知道,可以通过运行一个二分查找使得最坏情况下运行时间为C*(N*logN),还可以通过Hash算法将其优化到C*N时间复杂度
大部分情况使用O(N),即“大O记法”来表示算法运行时间增长的上界,比如1000*N=O(N^2),代表随着N的增大,1000*N的增长速度总是小于或等于N^2的增长速度。严格的定义如下:如果存在正常数c和$n_0$,使得当N>=$n_0$时T(N)<=cf(N),则记为T(N)=O(f(N))。
使用大O计法来表示前面那段程序在最坏情况的时间复杂度就是 C*(N^2)=O(N^2)。另外一个重要结论是:
当N越来越大的时候,logN增大得非常慢,N*logN还可以接受,N^2比前面两者要大得多。
如果以上看起来很复杂,你只需要像我一样知道O(NlogN)比O(N^2)好就可以了。
偶尔也可能使用Ω(Omega),θ(theta)等符号,感兴趣的话可以去网上查找这些符号的定义,不知道也关系不大。
三.插入(Insertion)排序
插入排序是唯一一种被广泛应用的平方级(quodradic)排序算法,大量编程语言基础库(STL,JDK等)都能见到它矫健的身影,下面先上代码:
插入排序的原理有些类似于打扑克牌抓牌的过程,脑补一下你在玩升级这类扑克牌游戏时抓牌的过程,你就学会了插入排序,唯一的区别是当你新抓一张牌时,你一眼就能找到要插入的位置,而计算机需要一定次数的比较才能找到。数组如果一开始是逆序,则插入排序每抓一张牌都要将其跟手上每一张牌进行比较,从而找到正确的插入位置。这就是插入排序的最坏情况。从中很容易得出,插入排序的时间复杂度是O(N^2),而你“抓牌”的时间复杂度是O(N)。
你可能还听过几种平方级算法,比如说选择排序和冒泡排序,它们的应用场景少的可怜。大多数时候它们仅仅用来教计算机初学者如何写代码,国外的一些视频教程甚至直接称之为“玩具”或者“垃圾”算法。你可能会觉得奇怪,为什么同为平方级算法,插入排序如此流行,而选择排序的意义跟HelloWorld差不多,先上一张图
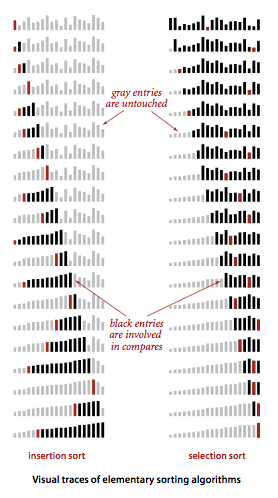
上图描述了插入排序与选择排序的区别,可以看到在平均情况下,插入排序需要进行的比较次数比选择排序几乎少一半。插入排序只有在最坏的情况(输入数组是逆序)下时间复杂度是O(N^2),在最好的情况(数组已经有序)下是O(N),而冒泡排序与选择排序无论在什么情况下都是O(N^2)。这个例子也可以说明,比较两种算法,不能仅仅看它们在最差情况下的时间复杂度。
以上说明了如果我们只能选择平方级算法,应该优先考虑插入排序。而大牛们早已证明了最优的排序算法(基于比较的)复杂度是O(N*logN)。那又是什么让插入排序得以与这些高级算法竞争呢?
后面你会看到,O(N*logN)排序算法大多基于分治(Divide and Conquer)思想,而该思想的实现大多基于递归,在大多数编程语言中,调用函数的开销是非常大的,需要为每个函数分配栈空间,有时还需要保存其作用域直到整个算法结束,这个过程稍有不慎就会得到一个StackOverFlow(栈空间溢出),部分函数式编程语言使用尾递归优化(Tail Call Optimization)来缓解这类问题。总之在大多数情况下,函数调用语句无论是时间还是空间花费都高于执行普通语句。于是基于递归的高级排序算法在处理小型数组时性能甚至低于插入排序。
结论:插入排序适用于初始状态就接近有序的大型数组,此时它的复杂度几乎是线性的,但它更加主要的应用场景是处理微型数组。大量基于递归的排序算法,在递归函数调用前判断当前需要处理的数组大小,如果输入小于某个常量则直接执行插入排序,至于这个常量的大小则因使用环境而异,有人说大概5-15,有人说5-20
四.希尔(Shell)排序
前面提到,插入排序在处理大规模随机数组时是非常低效的,它最主要的缺陷在于每次只交换相邻的两个元素,元素只能一步一步的从数组的一端移动到另一端。Donald Shell在此基础上,对其进行了一个小小的改进,于是有了以他名字命名的希尔排序。希尔排序是第一批突破平方级别的算法之一,然而理解它的性能至今仍是一项挑战。上代码:
希尔排序与选择排序最主要的差别在于引入了一个step变量(指步长,一些书上喜欢用gap或h来表示),这使得每次交换元素位置,都可以使该元素向其最终位置跨一大步,看图:
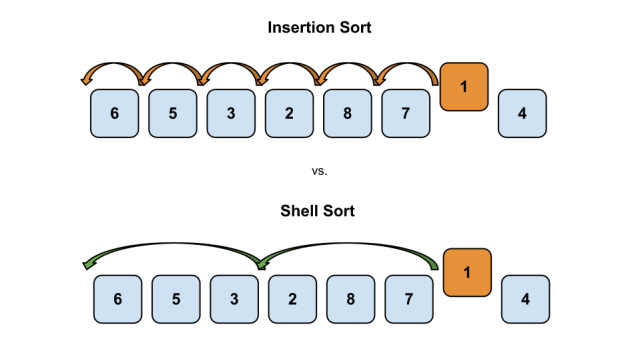
随着排序的进行,数组越来越接近有序,步长也越来越小,直到step=1,此时希尔排序就变得跟插入排序一模一样了,但此时数组已经几乎完全有序了,还记得前面所说过的吗?对一个几乎有序的数组运行插入排序,其复杂度接近O(N)。整个过程看起来天衣无缝,然而其中隐藏着一个难点,应该使用怎样的步长序列?必须要考虑的因素有两点:
- 当改变步长的时候,如何保证新的步长不会打乱之前排序的结果?这不会影响最终排序的正确性,因为只要步长在减小,数组永远都只会朝着更加有序的方向迈进,但这却是影响希尔排序效率的关键。因为这涉及到完成排序的过程中,算法做了多少无用功。
- 如何保证每一个步长都是有意义的?来看一个例子,假设有一个数组[1,5,2,6,3,7,4,8],使用步长序列[4,2,1]对其进行排序,过程如图:
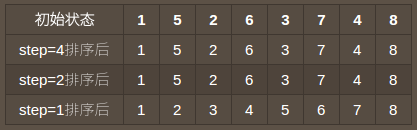
这就相当于进行了一次低效的插入排序,因为在step=1之前,程序什么也没干,偶数位置永远不会与基数位置进行比较。而下文你会看到,[4,2,1]正是按照Shell本人一开始推荐的增量算法得来的。
以上应该足以说明寻找好的步长序列是一件非常困难的事。好在总有人愿意为我们做这件事,下面列出一些流行的增量序列:
- Shell增量:N/2,N/4,N/8...1
即初始步长选择N/2,后面每次取半直到步长为1,它出自Shell本人且非常容易用代码表达,因此而流行,我看到现在的一些文章都还在使用它。然而前面的例子已经可以看出,在一些特定输入下它非常低效,它在最坏情形的时间复杂度仍是O(N^2)。事实上除了这个序列,后面列出的序列在最坏情形的性能差距都不会很大。 - Hibbard增量:1,3,7,15...,2^k-1
最坏情形$\theta(N^{3/2}))$,平均复杂度大概是$O(N^{5/4})$,它的重要改进是相邻的增量之间没有公因子。而Shell增量之所以不好,因为它的增量之间并非互素,如果这很难理解就回顾一下上面使用[4,2,1]步长排序的例子,再脑补一下用[6,3,1]步长对[1,5,9,2,6,10,3,7,11,4,8,2]排序的情形。 - Knuth增量:1,4,13,40,...,(3^k - 1)/2
同为$\theta(N^{3/2})$,但貌似这个序列使用最广泛,即便现在已经证实了有更好的步长序列。 - Sedgewick增量:1,5,19,41,109...
最坏情形$O(N^{4/3})$,这是已知复杂度(还有一些实践起来效果很好的序列至今没有算出复杂度)的最佳序列,通过
$$1,19,109,505,...,9\times4^k-9\times2^k+1$$$$5,41,209,929,...,2^{k+2}\times(2^{k+2}-3)+1$$
两个算式综合而来,依据基偶性交叉选择两个算式的结果即可。
关于希尔排序的研究仍在继续,目前还没有人证明某个序列是最优的,理解希尔排序在不同的序列下的复杂度是非常高端的学问。好在实现它是非常简单的。把大牛们的工作结晶放在一个常量数组中就可以很容易的实现希尔排序。
结论:希尔排序处理中等大小的数组是非常不错的,对于非常大的输入也可以在有限的时间内完成。它的优势在于编程简单,无需额外空间。Sedgewick在其书中的原话是“如果你需要解决一个排序问题,有没有系统排序函数可用(例如直接接触硬件或是运行嵌入式系统中的代码),可以先用希尔排序,然后再考虑是否值得将它替换成更加复杂的排序算法。”
下一篇文章来聊剩下两个算法。
本文参考链接